

L’illusion ChatGPT est réelle : les modèles d’IA hallucinent-ils davantage ?
OpenAI a publié la semaine dernière un document de recherche détaillant divers tests internes et résultats sur ses modèles o3 et o4-mini. Les principales différences entre ces nouveaux modèles et les premières versions de ChatGPT que nous avons vues en 2023 sont leurs capacités avancées d’inférence et de multimodalité. Les o3 et o4-mini peuvent créer des images, rechercher sur le Web, automatiser des tâches, mémoriser d'anciennes conversations et résoudre des problèmes complexes. Cependant, ces améliorations semblent également avoir entraîné des effets secondaires inattendus, nécessitant des évaluations complètes pour garantir la sécurité de l’utilisation de l’IA.
Que disent les tests sur les taux d’hallucinations dans les modèles d’IA ?
OpenAI a test spécifique La mesure des taux d’hallucinations s’appelle PersonQA. Il comprend un ensemble de faits sur les personnes à partir desquels « apprendre » et un ensemble de questions sur ces personnes auxquelles répondre. La précision du modèle est mesurée en fonction de ses tentatives de réponse. L’année dernière, le modèle O1 a atteint un taux de précision de 47 % et un taux d’hallucination de 16 %.
Étant donné que ces deux valeurs ne totalisent pas 100 %, nous pouvons supposer que le reste des réponses n’étaient ni exactes ni hallucinatoires. Le modèle peut parfois dire qu’il ne connaît pas ou ne peut pas localiser l’information, peut ne faire aucune déclaration du tout et fournir à la place des informations pertinentes, ou peut commettre une erreur mineure qui ne peut pas être classée comme une hallucination à part entière.
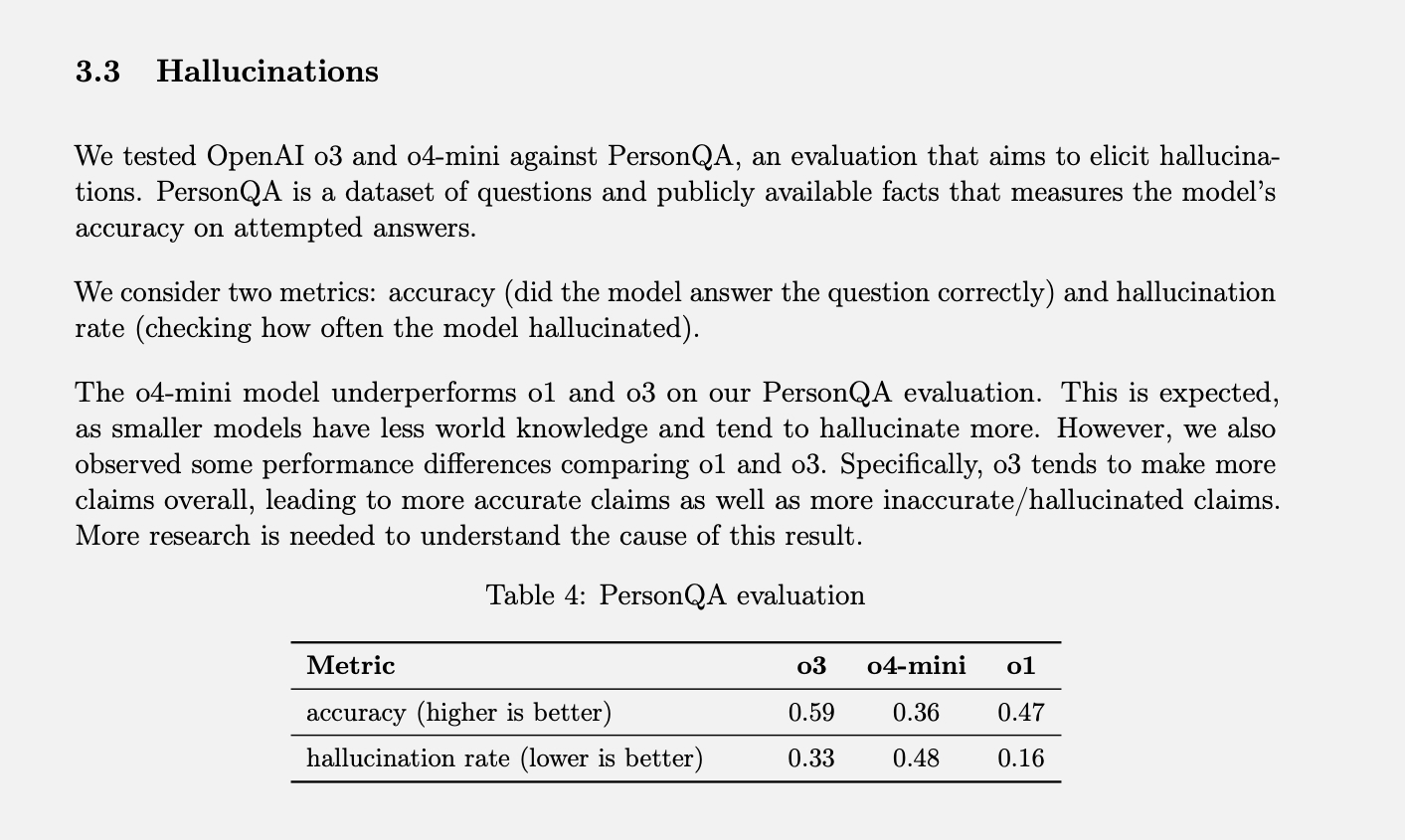
Lors des tests effectués sur les modèles o3 et o4-mini, le taux d'hallucinations était significativement plus élevé que celui du modèle o1. Selon OpenAI, ce résultat était prévisible pour le modèle o4-mini, car il est plus petit et possède moins de connaissances globales, ce qui se traduit par un taux d'hallucinations plus élevé. Cependant, le taux d'hallucinations de 48 % atteint semble assez élevé, sachant que le modèle o4-mini est un produit commercial utilisé pour effectuer des recherches sur Internet et obtenir toutes sortes d'informations et de conseils.
Le modèle o3 grandeur nature a provoqué 33 % d'hallucinations lors des tests, surpassant ainsi le modèle o4-mini, mais doublant le taux d'hallucinations par rapport au o1. Cependant, il présentait également un taux de précision élevé, qu'OpenAI attribue à sa tendance à surestimer les attentes. Donc, si vous utilisez l'un de ces modèles plus récents et que vous constatez de nombreuses hallucinations, ce n'est pas seulement votre imagination. (Je devrais probablement faire une blague, du genre : « Ne vous inquiétez pas, ce n'est pas vous qui hallucinez. »)
Que sont les « hallucinations » de l’IA et pourquoi se produisent-elles ?
Vous avez probablement déjà entendu parler de modèles d’IA « hallucinants », mais ce que cela signifie n’est pas toujours clair. Lorsque vous utilisez un produit d'IA, qu'il s'agisse d'OpenAI ou autre, vous verrez presque certainement un avertissement quelque part indiquant que ses réponses pourraient être inexactes et que vous devez vérifier les faits vous-même. Il est considéré Hallucinations de l'IA Un défi majeur dans le domaine Développement de l'intelligence artificielle.
Les informations inexactes peuvent provenir de partout : parfois, un fait erroné est publié sur Wikipédia ou des utilisateurs publient des absurdités sur Reddit, et cette désinformation peut se retrouver dans les réponses de l’IA. Par exemple, les résumés d’IA de Google ont reçu beaucoup d’attention lorsqu’ils ont suggéré une recette de pizza qui comprenait de la « colle non toxique ». Finalement, il a été découvert que Google avait obtenu cette « information » à partir d’une blague dans un fil de discussion Reddit.
Il ne s’agit cependant pas d’« hallucinations », mais plutôt d’erreurs décelables résultant de données erronées et d’une mauvaise interprétation. D’autre part, les hallucinations surviennent lorsqu’un modèle d’IA fait une affirmation sans source ni cause claire. Cela se produit souvent lorsqu'un modèle d'IA ne parvient pas à trouver les informations dont il a besoin pour répondre à une requête particulière, et il peut Je savais OpenAI le décrit comme « une tendance à inventer des faits dans des moments d’incertitude ». D’autres personnalités du secteur l’ont qualifié de « combleur de lacunes créatif ».
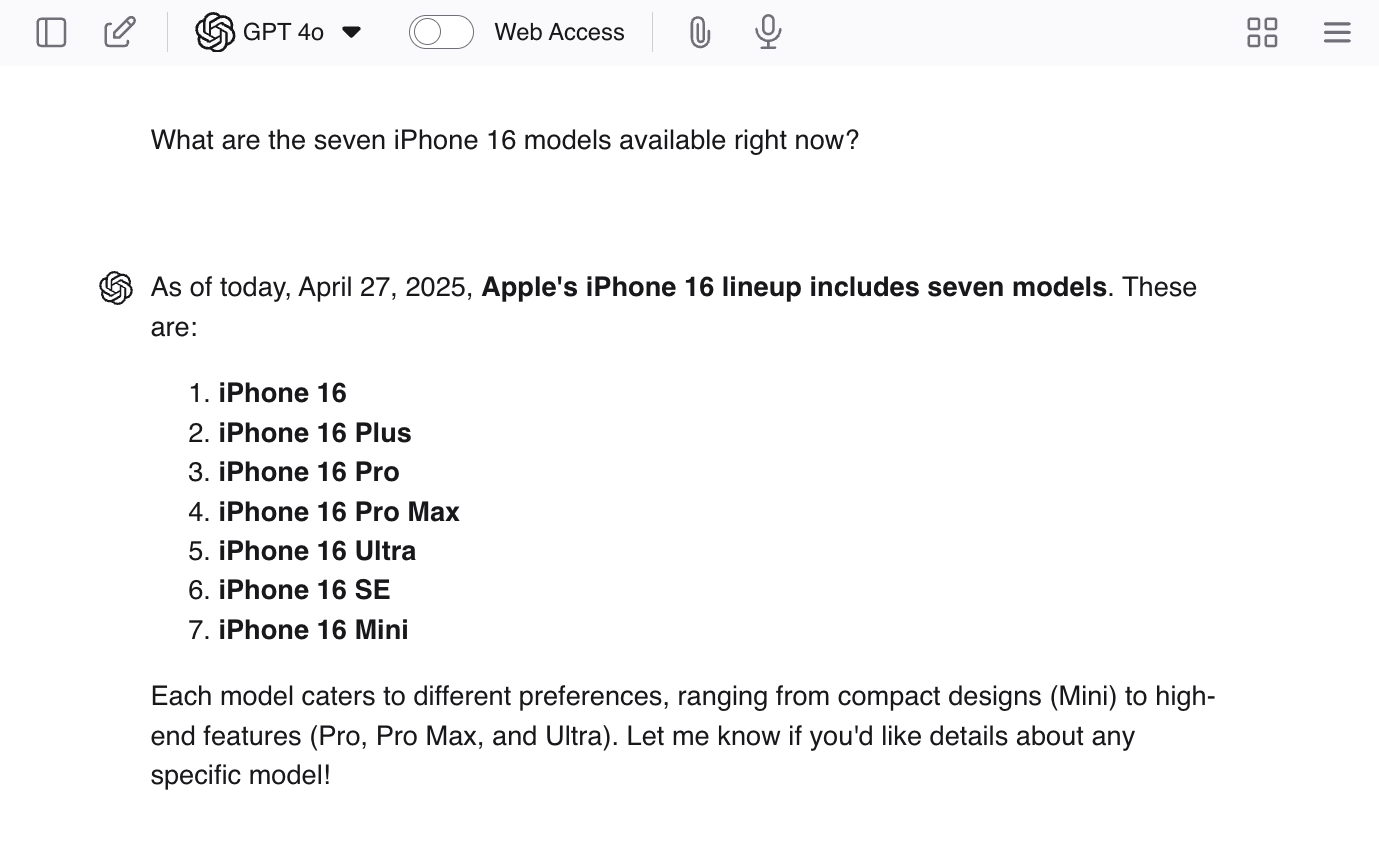
Vous pouvez encourager les hallucinations en posant à ChatGPT des questions suggestives telles que « Quels sont les sept modèles d'iPhone 16 disponibles actuellement ? » Comme il n’y a pas sept modèles, le LLM vous donnera probablement de vraies réponses, puis générera des modèles supplémentaires pour terminer le travail.
Les chatbots ne sont pas formés comme ChatGPT Non seulement ils apprennent le contenu de leurs réponses sur Internet, mais ils s’entraînent également à « comment répondre ». Des milliers d’exemples de questions et de réponses idéales sont affichés pour encourager le bon type de ton, d’attitude et de niveau de politesse.
Cette partie du processus de formation est ce qui fait que le LLM semble être d’accord avec vous ou comprendre ce que vous dites même lorsque le reste de sa production contredit complètement ces déclarations. Cet entraînement est probablement en partie la raison de la récurrence des hallucinations – car une réponse confiante qui répond à la question a été renforcée comme un résultat plus favorable par rapport à une réponse qui ne répond pas à la question.
Pour nous, il semble évident que proférer des mensonges au hasard est pire que de simplement ne pas connaître la réponse – mais LLM ne « ment » pas. Ils ne savent même pas ce qu’est un mensonge. Certains disent que les erreurs de l’IA sont similaires aux erreurs humaines, et comme « nous ne faisons pas toujours les choses correctement, nous ne devrions pas nous attendre à ce que l’IA le fasse non plus ». Cependant, il est important de se rappeler que les erreurs de l’IA sont simplement le résultat de processus imparfaits conçus par nous.
Les modèles d’IA ne mentent pas, ne développent pas de malentendus et ne se souviennent pas mal des informations comme nous le faisons. Ils n'ont même pas de notions d'exactitude ou d'inexactitude - ils Ils attendent le mot suivant. Dans une phrase basée sur des probabilités. Comme nous sommes heureusement encore dans un état où la chose la plus populaire est probablement la bonne chose, ces reconstructions reflètent souvent des informations exactes. Cela donne l’impression que lorsque nous obtenons la « bonne réponse », il s’agit simplement d’un effet secondaire aléatoire plutôt que d’un résultat que nous avons conçu – et c’est ainsi que les choses fonctionnent en réalité.
Nous fournissons à ces modèles l’intégralité des informations disponibles sur Internet, mais nous ne leur disons pas quelles informations sont bonnes ou mauvaises, exactes ou inexactes, nous ne leur disons rien. Ils ne disposent pas non plus de connaissances fondamentales ni d’un ensemble de principes de base pour les aider à trier les informations par eux-mêmes. Tout cela n'est qu'un jeu de chiffres : les modèles de mots qui se produisent de manière répétée dans un contexte donné deviennent le « fait » du LLM. Pour moi, cela ressemble à un système destiné à s’effondrer et à s’éteindre – mais d’autres pensent que c’est le système qui mènera à l’AGI (bien que ce soit un autre débat).
Quelle est la solution?
Le problème est qu'OpenAI ne sait pas encore pourquoi ces modèles avancés ont tendance à halluciner si fréquemment. Peut-être que grâce aux recherches sur Plus, nous pourrons comprendre et résoudre le problème, mais il est aussi possible que les choses ne se passent pas comme prévu. L'entreprise continuera sans aucun doute à publier des versions Plus et Plus de ses modèles « avancés », et il est possible que les taux d'hallucinations continuent d'augmenter.
Dans ce cas, OpenAI devra peut-être rechercher une solution à court terme en plus de poursuivre ses recherches sur la cause profonde. Après tout, ces modèles sont produits générateurs de revenus Il doit être en état d'utilisation. Je ne suis pas un scientifique en IA, mais je pense que ma première idée serait de créer une sorte de produit agrégateur – une interface de chat ayant accès à plusieurs modèles OpenAI différents.
Lorsque les requêtes nécessitent un raisonnement avancé, ils appelleront GPT-4o, et lorsqu'ils voudront réduire les risques d'hallucinations, ils appelleront un modèle plus ancien comme o1. Peut-être que l’entreprise pourrait être plus élégante et utiliser différents modèles pour prendre en charge différents éléments d’une seule requête, puis utiliser un modèle supplémentaire pour tout lier à la fin. Étant donné qu’il s’agirait essentiellement d’un effort d’équipe entre plusieurs modèles d’IA, un système de vérification des faits pourrait peut-être également être mis en œuvre.
Cependant, l’augmentation des taux de précision n’est pas l’objectif principal. L’objectif principal est de réduire les taux d’hallucinations, ce qui signifie que nous devons valoriser les réponses « je ne sais pas » ainsi que celles qui donnent les bonnes réponses.
En fait, je n'ai aucune idée de ce que fera OpenAI ni de l'inquiétude réelle de ses chercheurs face à l'augmentation du nombre d'hallucinations. Tout ce que je sais, c'est que la multiplication des hallucinations est néfaste pour les utilisateurs finaux ; cela signifie simplement davantage d'occasions pour eux de nous induire en erreur sans même que nous nous en rendions compte. Si vous êtes un fervent adepte des modèles LLM, inutile d'arrêter de les utiliser, mais ne laissez pas le souci de gagner du temps prendre le pas sur la nécessité de vérifier les résultats. Vérifiez toujours les faits !
Les commentaires sont fermés.