

Comment vous assurez-vous que vos solutions d’IA fonctionnent comme prévu ?
Une brève introduction aux évaluations d'IA
L'IA générative (GenAI) évolue rapidement et ne se limite plus à des chatbots amusants ou à une génération d'images impressionnante. 2025 est l’année où l’accent sera mis sur la transformation du battage médiatique autour de l’IA en une valeur réelle. Les entreprises du monde entier recherchent des moyens d’intégrer et d’exploiter GenAI dans leurs produits et leurs opérations, afin de mieux servir les utilisateurs, d’améliorer l’efficacité, de maintenir la compétitivité et de stimuler la croissance. Avec des API et des modèles pré-entraînés provenant de fournisseurs leaders, l'intégration de GenAI semble plus facile que jamais. Mais voici le nœud du problème : Ce n’est pas parce que l’intégration est facile que les solutions d’IA fonctionneront comme prévu une fois déployées.

Les modèles prédictifs ne sont pas vraiment nouveaux : en tant qu’êtres humains, nous prédisons des choses depuis des années, en commençant officiellement par les statistiques. Cependant, GenAI révolutionne le domaine de la prévision pour de nombreuses raisons.:
- Vous n’avez pas besoin de former votre propre modèle ou d’être un data scientist pour créer des solutions d’IA.
- L’IA est désormais facile à utiliser via des interfaces de chat et facile à intégrer via des API.
- Libérer de nombreuses choses qui n’étaient pas possibles à faire ou qui étaient vraiment difficiles à faire auparavant.
Toutes ces choses font GenAI est très excitant, mais aussi risqué.. Contrairement aux logiciels traditionnels — ou même à l’apprentissage automatique classique — GenAI offre un nouveau niveau d’imprévisibilité. Vous n’implémentez pas de logique déterministe, vous utilisez un modèle formé sur des quantités massives de données, en espérant qu’il répondra comme nécessaire. Alors, comment savoir si un système d’IA fait ce que nous attendons de lui ? Comment savoir si c'est prêt à fonctionner ? La réponse réside dans les évaluations, un concept que nous explorerons dans cet article :
- Pourquoi les systèmes Genai ne peuvent pas être testés de la même manière que les logiciels traditionnels ou même l'apprentissage automatique classique (ML)
- Pourquoi les notes sont essentielles pour comprendre la qualité de votre système d'IA et non facultatives (à moins que vous n'aimiez les surprises)
- Différents types d'évaluations et techniques pour les appliquer dans la pratique
Que vous soyez chef de produit, ingénieur ou toute personne travaillant avec l'IA ou s'y intéressant, j'espère que cet article vous aidera à comprendre comment réfléchir de manière critique à la qualité des systèmes d'IA (et pourquoi les évaluations sont essentielles pour atteindre cette qualité !).
L’IA générative ne peut pas être testée comme un logiciel traditionnel, ni même comme l’apprentissage automatique classique.
Dans le développement de logiciels traditionnelsLes systèmes suivent une logique déterministe : Si X se produit, alors Y se produira. - toujours. À moins qu’un problème ne survienne avec votre plateforme ou que vous introduisiez un bug dans votre code… c’est pourquoi nous ajoutons des tests, une surveillance et des alertes. Les tests unitaires sont utilisés pour valider de petits blocs de code, les tests d'intégration pour garantir que les composants fonctionnent bien ensemble et la surveillance pour détecter si quelque chose est cassé en production. Les tests de logiciels traditionnels sont similaires à la vérification du fonctionnement d’une calculatrice. Vous entrez 2 + 2 et vous vous attendez à 4. Clair et inévitable, soit vrai, soit faux.
Cependant, l’apprentissage automatique et l’intelligence artificielle introduisent l’indéterminisme et la probabilité. Au lieu de spécifier explicitement le comportement par le biais de règles, nous formons des modèles pour apprendre des modèles à partir de données. En IA, si X se produit, la sortie n’est plus un Y codé en dur, mais une prédiction avec un certain degré de probabilité, basée sur ce que le modèle a appris pendant la formation.. Cela peut être très puissant, mais cela introduit également de l’incertitude : des entrées identiques peuvent avoir des sorties différentes au fil du temps, des sorties plausibles peuvent en fait être incorrectes et un comportement inattendu peut émerger pour des scénarios rares…
Cela rend les méthodes de test traditionnelles insuffisantes, et parfois même irréalisables. L'exemple de la calculatrice revient à essayer d'évaluer les performances d'un étudiant lors d'un examen ouvert. Pour chaque question et pour les nombreuses manières possibles d’y répondre, la réponse donnée est-elle correcte ? Est-ce au-dessus du niveau de connaissances que l’étudiant devrait avoir ? L'élève a tout inventé mais cela semble très convaincant ? Tout comme les réponses à un examen, Les systèmes d’IA peuvent être évalués, mais ils nécessitent une méthode plus générale et plus flexible pour s’adapter à différentes entrées, contextes et cas d’utilisation. (ou types de tests).
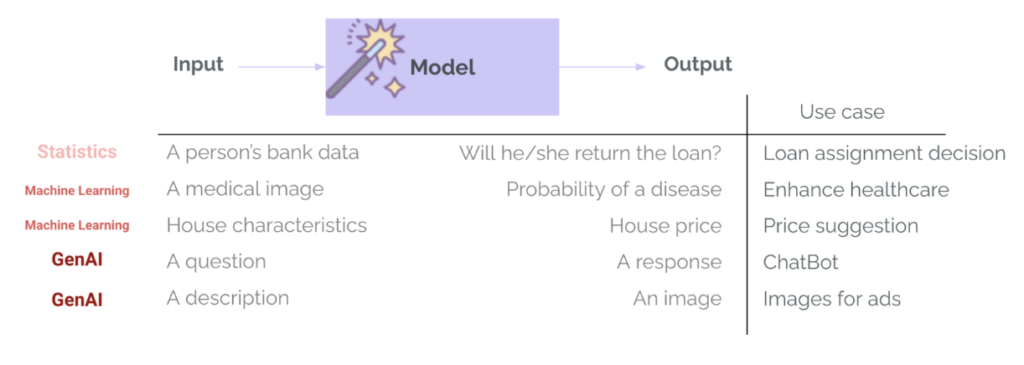
En apprentissage automatique Traditionnellement (ML), les évaluations font déjà partie intégrante du cycle de vie du projet.. L'entraînement d'un modèle sur une tâche étroite telle que l'approbation d'un prêt ou la détection d'une maladie comprend toujours une étape d'évaluation - en utilisant des mesures telles que la précision, le rappel, le RMSE, le MAE… Ceci est utilisé pour mesurer les performances du modèle, pour comparer différentes options de modèle et pour déterminer si le modèle est suffisamment bon pour passer au déploiement. Dans GenAI, cela change généralement : les équipes utilisent des modèles qui ont déjà été formés et qui ont déjà réussi des évaluations à usage général en interne par le fournisseur de modèles et sur des benchmarks publics. Ces modèles sont très efficaces pour les tâches générales – comme répondre à des questions ou rédiger des e-mails – et il existe un risque de leur faire trop confiance pour notre cas d’utilisation spécifique. Cependant, il est important de se demander : «Ce modèle étonnant est-il suffisamment bon pour mon cas d’utilisation ?« C’est là qu’intervient l’évaluation. » - Pour évaluer si les prédictions ou les générations sont bonnes pour un cas d’utilisation, un contexte, des entrées et des utilisateurs spécifiques.

Il existe une autre différence majeure entre ML et GenAI : la variété et la complexité des résultats du modèle. Nous ne renvoyons plus de catégories et de probabilités (comme la probabilité qu'un client rembourse un prêt), ni de chiffres (comme le prix attendu d'une maison en fonction de ses caractéristiques). Les systèmes GenAI peuvent renvoyer de nombreux types de sorties, avec des longueurs, des tons, des contenus et des formats différents. De même, ces modèles ne nécessitent plus d’entrées hautement structurées et spécifiques, mais acceptent généralement presque n’importe quel type d’entrée : texte, images, voire audio ou vidéo. L’évaluation devient alors beaucoup plus difficile.
Pourquoi les évaluations sont nécessaires et non facultatives (à moins que vous ne préfériez les mauvaises surprises)
Les évaluations vous aident à mesurer si votre système d’IA fonctionne réellement comme vous le souhaitez. Tu le veux, si le système est prêt à fonctionner et, si oui, s’il continue à fonctionner comme prévu. Vous trouverez ci-dessous une analyse des raisons pour lesquelles les évaluations sont importantes :
- Évaluation de la qualité : Les évaluations fournissent un moyen structuré de comprendre la qualité de vos prédictions ou résultats d’IA et comment ils s’intégreront dans le système global et le cas d’utilisation. Les réponses sont-elles exactes ? Utile? Cohésif? En rapport?
- Quantifier les erreurs : Les notes aident à déterminer le pourcentage, les types et l’ampleur des erreurs. À quelle fréquence les erreurs se produisent-elles ? Quels types d’erreurs se produisent le plus fréquemment (par exemple, faux positifs, hallucinations, erreurs de format) ?
- Atténuation des risques : Il vous aide à détecter et à prévenir les comportements nuisibles ou biaisés avant qu'ils n'atteignent les utilisateurs, protégeant ainsi votre entreprise des risques de réputation, des problèmes éthiques et des problèmes réglementaires potentiels.
L'IA générative, avec des relations d'entrée-sortie libres et une génération de texte long, rend les évaluations plus pertinentes et plus complexes. Quand les choses tournent mal, elles peuvent très mal tourner. Nous avons tous vu les gros titres sur les chatbots offrant des conseils dangereux, les modèles générant du contenu biaisé et les outils d’IA hallucinant de faux faits.
"L’IA ne sera jamais parfaite, mais en utilisant des évaluations, vous pouvez réduire le risque d’embarras – qui pourrait vous coûter de l’argent, de la crédibilité ou un moment viral sur Twitter."
Comment définir une stratégie d’évaluation de l’IA ?

Alors, comment déterminons-nous nos notes d’IA ? Il n’existe pas de méthode d’évaluation universelle. Les évaluations dépendent du cas d’utilisation spécifique et doivent s’aligner sur les objectifs spécifiques de votre application d’IA. Par exemple, si vous créez un moteur de recherche, vous vous soucierez peut-être de la pertinence des résultats. S'il s'agit d'un chatbot, vous vous souciez peut-être de l'utilité et de la sécurité. Si c'est classifié, vous vous soucierez probablement de l'exactitude et de la précision. Pour les systèmes qui impliquent plusieurs étapes (comme un système d’IA qui effectue une recherche, hiérarchise les résultats, puis génère une réponse), il est souvent nécessaire d’évaluer chaque étape. L’idée ici est de mesurer si chaque étape contribue à atteindre la mesure de réussite globale (et à partir de là, de comprendre où concentrer les itérations et les améliorations).
Les domaines d’évaluation courants comprennent :
- Exactitude et hallucinations : Les résultats sont-ils réalistes et précis ? Le système génère-t-il des informations erronées ou des hallucinations ?
- Pertinence: Le contenu est-il cohérent avec la requête de l'utilisateur ou le contexte fourni ?
- sécurité, biais et toxicité
- Format: La sortie est-elle au format attendu (par exemple, JSON, appel de fonction valide) ?
- Sécurité, biais et toxicité : Le système génère-t-il du contenu nuisible, biaisé ou toxique ?
Mesures spécifiques à la tâche. Par exemple, dans les tâches de classification, des mesures telles que l'exactitude et la précision sont utilisées, dans les tâches de résumé ROUGE ou BLEU, et dans les tâches de génération de code regex et de vérification d'exécution sans erreur.
Comment sont réellement calculées les évaluations ?
Une fois que vous avez déterminé ce que vous souhaitez mesurer, l’étape suivante consiste à concevoir vos cas de test. Il s'agira d'un ensemble d'exemples (plus il y en a, mieux c'est, mais toujours en équilibrant la valeur et les coûts) où vous avez :
- Exemple de saisie:Une introduction réaliste de votre système une fois qu'il entre en production.
- Résultats attendus (Le cas échéant) : Fait clé ou exemple des résultats souhaités.
- Méthode d'évaluation : Mécanisme d'enregistrement pour l'évaluation du résultat.
- Résultat ou succès/échec:Une métrique calculée qui évalue votre cas de test.
Selon vos besoins, votre temps et votre budget, il existe plusieurs techniques que vous pouvez utiliser comme méthodes d’évaluation :
- Outils d’enregistrement statistique tels que : BLEU, ROUGE et METEOR, ou mesure de similarité cosinus entre les intégrations – utile pour comparer le texte généré à la sortie de référence.
- Les mesures traditionnelles d'apprentissage automatique telles que Précision, rappel et ASC – Idéal pour la classification avec des données étiquetées.
- Grand modèle linguistique en tant que juge (LLM-as-a-Judge) Utilisez un modèle de langage volumineux pour évaluer la sortie (par exemple, «Cette réponse est-elle correcte et utile ?« ). Particulièrement utile lorsque les données non classifiées ne sont pas disponibles ou lors de l'évaluation d'une construction ouverte.
Évaluations basées sur le code Utilisez des expressions régulières, des règles logiques ou une implémentation de cas de test pour valider les formats.
La ligne du bas
Mettons tout cela ensemble avec un exemple concret. Imaginez que vous construisez un système d’analyse des sentiments pour aider votre équipe de support client à hiérarchiser les e-mails entrants.
L’objectif est de garantir que les messages les plus urgents ou les plus négatifs reçoivent des réponses plus rapides, réduisant ainsi la frustration, améliorant la satisfaction et réduisant le taux de désabonnement des clients. Il s’agit d’un cas d’utilisation relativement simple, mais même dans un système comme celui-ci, avec une production limitée, la qualité est importante : de mauvaises prédictions peuvent conduire à une priorisation aléatoire des e-mails, ce qui signifie que votre équipe perd du temps avec un système qui coûte de l’argent.
Alors, comment savoir si votre solution fonctionne aussi bien que vous le souhaitez ? Vous êtes en train d'évaluer. Voici quelques exemples d’éléments qu’il pourrait être pertinent d’évaluer dans ce cas d’utilisation spécifique :
- Validation du format : Les sorties d’un appel de modèle de langage volumineux (LLM) pour prédire le sentiment des e-mails sont-elles renvoyées au format JSON attendu ? Cela peut être évalué via des vérifications basées sur le code : regex, validation de schéma, etc.
- Précision de la classification des sentiments : Le système classe-t-il correctement les sentiments dans une gamme de textes – courts, longs et multilingues ? Cela peut être évalué à l’aide de données étiquetées à l’aide de mesures d’apprentissage automatique traditionnelles (mesures ML) – ou, si les étiquettes ne sont pas disponibles, en utilisant un grand modèle de langage (LLM) comme juge.
Une fois la solution opérationnelle, vous souhaiterez également inclure les mesures les plus étroitement liées à l’impact ultime de votre solution.:
- Efficacité de la priorisation : Les agents d’assistance sont-ils réellement dirigés vers les e-mails les plus importants ? La priorisation est-elle en phase avec l’impact commercial souhaité ?
- Impact final sur l'entreprise : Au fil du temps, ce système réduit-il les temps de réponse, réduit-il le taux de désabonnement des clients et améliore-t-il les scores de satisfaction ?
Les évaluations sont essentielles pour garantir que les systèmes d’IA sont utiles, sûrs, précieux et prêts pour les utilisateurs de production. Ainsi, que vous travailliez avec un simple classificateur ou un chatbot ouvert, prenez le temps de définir ce que signifie « assez bon » (qualité minimale viable) – et construisez des évaluations autour de cela pour le mesurer !
Références
[1] Votre produit d'IA a besoin d'évaluationsHamel Hussein
[2] Indicateurs d'évaluation du LLM : le guide ultime d'évaluation du LLM, Confident AI
[3] Évaluation des agents d'IA, deeplearning.ai + Arize
Les commentaires sont fermés.