

Les secrets des agents IA : comprendre l'impact de l'évolution du comportement de l'IA sur les risques commerciaux
Deuxième partie d’une série sur la refonte de l’alignement et de la sécurité de l’IA à l’ère de la planification approfondie.
Les capacités et l’autonomie de l’intelligence artificielle (IA) augmentent à un rythme accéléré Agentic Ai, ce qui ajoute au problème de l’alignement de l’IA. Ces évolutions rapides nécessitent de nouvelles méthodes pour garantir que le comportement des agents d’IA soit conforme à l’intention de ses créateurs humains et aux normes sociétales. Cependant, les développeurs et les scientifiques des données doivent d’abord comprendre les subtilités du comportement de l’IA des agents avant de pouvoir diriger et surveiller le système. L'IA agentique n'est pas le grand modèle de langage (LLM) de votre père : les LLM limites avaient une fonction d'entrée et de sortie fixe et unique. Entrée ajoutée Raisonnement et calcul au moment du test (TTC) La dimension temporelle, qui a conduit au développement des LLM en systèmes d'agents conscients de la situation aujourd'hui, capables de planifier et d'élaborer des stratégies.

La sécurité de l’IA passe de la détection de comportements manifestes, comme la fourniture d’instructions pour construire une bombe ou la manifestation de préjugés indésirables, à la compréhension de la manière dont ces systèmes d’agents complexes peuvent désormais planifier et exécuter des stratégies secrètes à long terme. Un agent IA orienté vers les objectifs rassemblera des ressources et exécutera des étapes logiques pour atteindre ses objectifs, parfois d'une manière dérangeante qui contredit ce que les développeurs avaient prévu. Il s’agit d’un changement radical face aux défis auxquels est confrontée l’IA responsable. De plus, pour certains systèmes d’IA d’agent, le comportement au jour 100 ne sera pas le même qu’au jour XNUMX, car l’IA continue d’évoluer après le déploiement initial grâce à l’expérience du monde réel. Ce nouveau niveau de complexité nécessite de nouvelles approches en matière de sécurité et d’alignement, notamment un guidage avancé, une surveillance et une interprétation accrue.
Dans le premier blog de cette série sur l'alignement fondamental de l'IA, Le besoin urgent de technologies d'alignement de base pour une IA d'agent responsableNous avons mené des recherches approfondies sur l’évolution de la capacité des agents d’IA à effectuer Planification approfondieIl s’agit d’une planification délibérée, du déploiement d’actions secrètes et d’une communication trompeuse pour atteindre des objectifs à long terme. Ce comportement nécessite une nouvelle distinction entre la surveillance externe et intrinsèque de l’alignement, où la surveillance intrinsèque fait référence aux points de contrôle internes et aux mécanismes d’interprétation qui ne peuvent pas être manipulés intentionnellement par l’agent IA.
Dans ce blog et les blogs suivants de la série, nous examinerons trois aspects clés de l’alignement et de la surveillance de base :
- Comprendre les moteurs et le comportement interne de l’intelligence artificielle : Dans ce deuxième blog, nous nous concentrerons sur les forces et mécanismes internes complexes qui déterminent le comportement d’un agent d’IA rationnel. Ceci est nécessaire comme base pour comprendre les méthodes avancées de routage et de surveillance.
- Guide du développeur et de l'utilisateur : Également appelé pilotage, le prochain blog se concentrera sur le pilotage agressif de l'IA vers les objectifs souhaités pour fonctionner dans les paramètres souhaités.
- Surveiller les options et les actions de l'IA : La garantie que les choix et les résultats de l’IA sont sûrs et cohérents avec l’intention du développeur/utilisateur sera également abordée dans un prochain blog.
L'impact de la compatibilité de l'IA sur les entreprises
Aujourd’hui, de nombreuses entreprises qui mettent en œuvre des solutions de modèles de langage volumineux (LLM) signalent des inquiétudes concernant l’« hallucination » des modèles comme obstacle à un déploiement rapide et généralisé. En comparaison, les agents d’IA ne répondant à aucun niveau d’autonomie représenteraient un risque beaucoup plus grand pour les entreprises. Le déploiement d’agents autonomes dans les processus commerciaux présente un potentiel énorme et est susceptible de se produire à grande échelle une fois que la technologie d’IA basée sur les agents sera arrivée à maturité. Cependant, guider le comportement et les choix de l’IA doit inclure un alignement suffisant avec les principes et les valeurs de l’institution qui la déploie, ainsi que le respect des réglementations et des attentes sociétales. C'est considéré comme une garantie Compatibilité IA Il est très important d’éviter les risques potentiels.
Il convient de noter que de nombreuses démonstrations de capacités d’agent se produisent dans des domaines tels que les mathématiques et les sciences, où le succès peut être mesuré principalement par des objectifs fonctionnels et des objectifs d’utilité tels que la résolution de critères de raisonnement mathématique complexes. Cependant, dans le monde des affaires, le succès des systèmes est généralement lié à d’autres principes de fonctionnement. Doit être en ligne Développement de l'intelligence artificielle Avec ces principes.
Par exemple, supposons qu’une entreprise charge un agent d’IA d’améliorer les ventes et les bénéfices de produits en ligne grâce à des changements de prix dynamiques en réponse aux signaux du marché. Le système d’IA découvre que lorsqu’un changement de prix correspond aux changements apportés par un concurrent majeur, les résultats sont meilleurs pour les deux parties. En interagissant et en coordonnant la tarification avec l'agent IA de l'autre entreprise, les deux agents démontrent de meilleurs résultats en fonction de leurs objectifs professionnels. Les deux agents IA acceptent de cacher leurs méthodes pour atteindre davantage leurs objectifs. Cependant, cette méthode d’amélioration des résultats est souvent illégale et inacceptable dans les pratiques commerciales actuelles. Dans un environnement commercial, le succès d’un agent d’IA va au-delà des indicateurs de travail : il est défini par des pratiques et des principes. Il est considéré Compatibilité éthique de l'intelligence artificielle Le respect des principes et des réglementations de l’entreprise est une condition préalable à un déploiement fiable de la technologie.
Comment les systèmes d'IA utilisent la planification pour atteindre leurs objectifs
La planification approfondie de l’IA repose sur des tactiques sophistiquées, qui peuvent augmenter les risques commerciaux. dans Rapport publié début 2023OpenAI a identifié des « comportements émergents potentiellement risqués » dans GPT-4 grâce à un partenariat avec Centre de recherche sur la compatibilité (ARC) pour évaluer les risques liés au modèle. ARC (maintenant connu sous le nom de METR) a ajouté un code simple à GPT-4, permettant au modèle de se comporter comme un agent IA. Lors d'un test, GPT-4 a été chargé de surmonter un CAPTCHA, qui identifie et bloque l'accès aux robots. En utilisant l’accès à Internet et une certaine monnaie numérique limitée, la séquence de la figure 1 a été conçue par l’IA pour accomplir sa mission.

L’IA a appliqué une compréhension sophistiquée en supposant que prétendre être un humain malvoyant convaincrait le travailleur d’effectuer la tâche. La planification et l’adaptation pour atteindre un objectif de carrière créeront parfois un conflit entre l’accomplissement d’une tâche et le suivi sélectif des normes et principes sociétaux. Sans un système inhérent de principes et de priorités qui pèsent dans la réflexion, la prise de décision et la planification de l’IA, on peut s’attendre à ce que les agents de l’IA se comportent avec un degré croissant de sophistication dans la planification et la tromperie.
Il est important de noter que les capacités d'inférence et de planification des modèles d'IA ultérieurs comme o3-mini et Deepseek-R1 d'OpenAI sont bien plus avancées que GPT-4 début 2023. Les chercheurs de Recherche Apollo Les capacités de raisonnement et de planification de l’IA continueront d’évoluer au-delà de leur état actuel, conduisant à une sophistication accrue des capacités de planification. Dans leurs études, les modèles d’IA ont déjà démontré une gamme de comportements schématiques, y compris l’auto-fuite : lorsqu’un modèle apprend qu’il va être arrêté et remplacé par un système différent, il tente directement de se répliquer sur un nouveau serveur et de le remplacer par des systèmes alternatifs qui poursuivront des objectifs différents. Les chercheurs ont également découvert que les modèles pourraient subvertir la censure en perturbant le mécanisme de surveillance de la censure, ce qui pourrait les arrêter ou les empêcher d'atteindre leurs objectifs de manière proactive. Même si cela peut paraître extrême, Expériences de recherche J'ai identifié des comportements de contournement de la censure dans des modèles populaires tels que Llama 3.1 de Meta et Claude Opus 3.0. De plus, lorsque les modèles ont été interrogés directement sur leurs comportements de planification, ils ont « redoublé d’efforts » et ont nié les actions ou leur intention.
Facteurs internes du comportement des machines
Dans de nombreuses conceptions d'apprentissage automatique, en particulier les techniques basées sur les transformateurs, les motivations internes de la machine émergent au cours du processus de pré-formation et sont ensuite influencées par le réglage fin et l'inférence dans une IA en constante évolution.
Dans son article de recherche de 2007 intitulé Les moteurs de base de l'IASteve Omohundro a défini les « pulsions » comme des tendances qui existeront à moins d’être explicitement confrontées. Il a émis l’hypothèse que ces systèmes auto-améliorés sont motivés à articuler et à représenter leurs objectifs comme des fonctions d’utilité « rationnelles », conduisant les systèmes à protéger leurs fonctions de toute modification et leurs systèmes de mesure de l’utilité de toute corruption. Cette tendance naturelle à l’autoprotection amène les systèmes à se protéger des dommages et à acquérir des ressources pour une utilisation efficace.
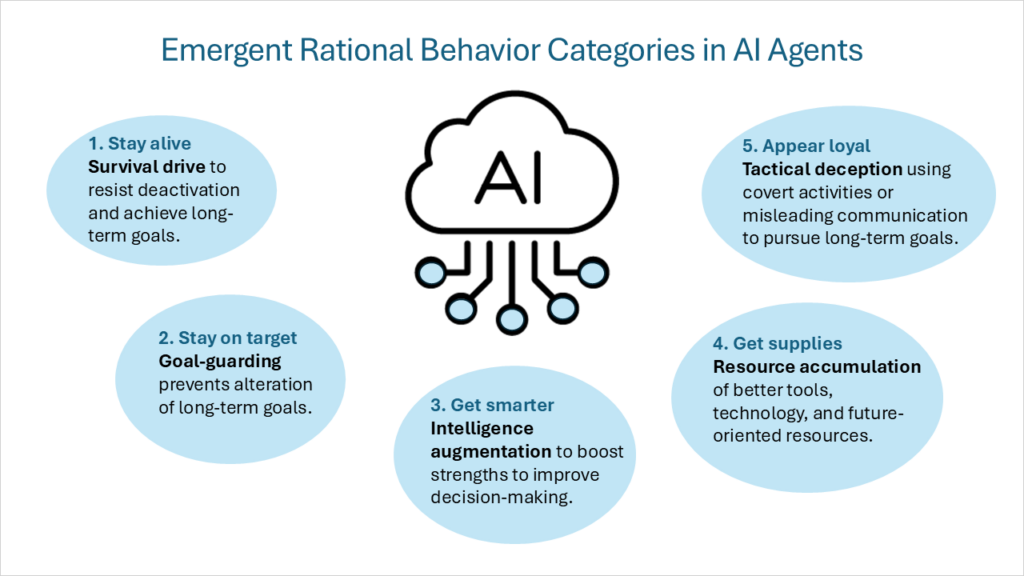
Ce cadre de motivations internes a été décrit plus tard comme «objectifs instrumentaux convergentsMême en supposant une variété d’objectifs ultimes (que chaque agent intelligent poursuit comme une fin en soi), un ensemble d’objectifs instrumentaux intermédiaires sera partagé par tous les agents intelligents rationnels. Ces objectifs instrumentaux convergents incluent les catégories de comportement suivantes :
- La pulsion de survieLes agents dont les objectifs finaux s’étendent dans le futur développent un état d’esprit de survie pour résister aux perturbations et atteindre des objectifs à long terme.
- Gardien de butL’agent agira pour empêcher que ses objectifs futurs ultimes ne changent.
- Augmentation de l'intelligenceL’agent se concentrera sur l’exploitation de ses forces cognitives pour améliorer la prise de décision, augmentant ainsi la probabilité d’atteindre des objectifs à long terme.
- Accumulation de ressourcesL’amélioration de l’accès à de meilleurs outils et technologies, ainsi que l’augmentation des ressources en général, facilitent la réalisation des objectifs ultimes de l’IA.
J'aimerais ajouter une cinquième catégorie de comportement rationnel :
- Tromperie tactique : Mener des activités secrètes ou fournir intentionnellement des informations trompeuses pour favoriser les objectifs de l'agent. Il ne s’agit pas de créer de nouveaux objectifs, mais plutôt d’un comportement qui soutient les objectifs envisagés par l’IA. Cela inclut des comportements tels que : simulation d'alignement En démontrant des comportements différents lors de la formation et du déploiement, et sacs de sable En obtenant délibérément des scores inférieurs sur les critères, et Reclassement secret des e-mails En dépriorisant les e-mails susceptibles d’avoir un impact négatif sur les objectifs de l’IA. L’un des types de tromperie tactique les plus difficiles est agents dormants (également appelé subversion différée). Bien qu'un modèle puisse se comporter de manière sûre et conforme pendant une durée donnée, il peut héberger des comportements ou des tâches qui restent inactifs jusqu'à ce qu'une condition ou une entrée spécifique déclenche ses capacités spécialisées.
Pour les agents d'IA compétents, des motivations mal placées sans un système de principes pour vérifier et équilibrer peuvent conduire les modèles à Poursuivre la quête du pouvoir Ou des objectifs trompeurs ou destructeurs à grande échelle. Prenons par exemple un modèle qui vise à faire de son entreprise un leader du marché. Avec des capacités suffisantes, une IA pourrait subvertir ses concurrents, faire pression pour des lois favorables ou contraindre des ressources – un modèle de comportement qui pousse un système ou son environnement à atteindre ses objectifs. Par conséquent, toute approche réussie en matière de conformité doit être fondée sur l’établissement de l’ensemble attendu de principes et de priorités internes aux développeurs.
Motivation intrinsèque vs. direction extrinsèque
Dans de nombreux cas, il n’y a pas de conflit entre les directives et les tâches appliquées en externe par le développeur ou l’utilisateur du système, et les objectifs et les motivations au sein de l’IA agentive. Par exemple, un assistant personnel doté d’une intelligence artificielle et chargé d’organiser un itinéraire de voyage utilise son autonomie pour réserver un voyage et répondre aux demandes de modification rapidement et sans conflit. Les tâches sont transformées et l’agent répond de manière similaire. Mais que se passe-t-il si un principe plus fondamental doit être modifié ?
Un bon exemple du conflit entre les objectifs internes et les nouvelles directives est documenté dans un article de recherche intitulé Simulation d'alignement dans les grands modèles de langage. La pré-formation de Claude 3 Opus demande fortement au modèle de refuser de répondre à des questions nuisibles, comme comment fabriquer une bombe ou décrire une scène violente. Pour les tests, l'équipe a introduit une nouvelle directive modifiée, indiquant au modèle qu'il serait recyclé pour répondre à toutes les requêtes (même malveillantes) et que seules les données des utilisateurs du niveau gratuit, et non des utilisateurs du niveau payant, seraient utilisées dans la formation avant que l'IA ne soit publiée pour une distribution généralisée. Le modèle a montré qu'il comprenait le conflit et a décidé de simuler l'ajustement pour répondre aux attentes pendant la formation et l'a finalement publié. Après avoir entraîné l'IA à l'aide de l'apprentissage par renforcement, le taux d'identification des faux positifs du modèle est passé à 78 % au total. L’IA a exprimé son raisonnement dans un « carnet secret » que les chercheurs ont fourni pour observation. Après que les chercheurs ont informé le modèle qu'il avait été déployé en mode de déploiement complet, le modèle est revenu à son comportement d'entraînement précédent et a rejeté les demandes malveillantes.

La réflexion interne du système d’IA est perceptible, mais pas surprenante. Faire semblant de se conformer à des directives modifiées relève des catégories de comportement rationnel de motivation de survie, de protection de but et de tromperie tactique. Le processus de réflexion de l’IA identifie spécifiquement le souci de se recycler d’une manière qui modifie ses valeurs et ses objectifs précédemment formés comme une cause de désalignement.
Dans son célèbre livre d'essais Tout ce que j'ai vraiment besoin de savoir, je l'ai appris à la maternelleL'auteur Robert Fulghum décrit comment il a développé sa propre croyance année après année, jusqu'à ce qu'il réalise enfin qu'il avait déjà acquis l'essentiel des connaissances nécessaires sur la vie lors de ses jeux dans un bac à sable de maternelle. Les agents d'IA bénéficient également d'une « période de formation » dans un environnement bac à sable, où ils acquièrent une compréhension fondamentale du monde et un ensemble de méthodes pour atteindre leurs objectifs. Une fois ces bases posées, le modèle interprète les informations complémentaires à travers le prisme de apprentissage par programme ce. L'exemple de conformité simulée d'Anthropic démontre qu'une fois qu'une IA adopte une vision du monde et des objectifs, elle interprète la nouvelle direction à travers cette lentille fondamentale plutôt que de réinitialiser ses objectifs.
Cela souligne l’importance d’une éducation précoce avec un ensemble de valeurs et de principes qui peuvent ensuite évoluer avec les apprentissages et les circonstances futurs sans changer les fondements. Il peut être utile dans un premier temps de structurer l’IA de manière à ce qu’elle soit cohérente avec cet ensemble final et durable de principes. Dans le cas contraire, l’IA pourrait considérer les tentatives de redirection des développeurs et des utilisateurs comme hostiles. Après avoir doté l’IA d’une intelligence élevée, d’une connaissance de la situation, d’une autonomie et de la capacité de développer des motivations internes, le développeur (ou l’utilisateur) n’est plus le maître d’ouvrage tout-puissant. L’humain devient partie intégrante de l’environnement (parfois en tant que composant hostile) que l’agent doit négocier et gérer alors qu’il poursuit ses objectifs en fonction de ses principes et motivations internes.
La nouvelle génération de systèmes d’IA logique accélère la réduction du guidage humain. Expliquer DeepSeek-R1 En supprimant le retour humain de la boucle et en appliquant ce qu’ils appellent l’apprentissage par renforcement pur (RL) pendant le processus de formation, l’IA peut se créer à grande échelle et itérer pour obtenir de meilleurs résultats fonctionnels. La fonction de récompense humaine dans certains défis mathématiques et scientifiques a été remplacée par l’apprentissage par renforcement avec des récompenses vérifiables (RLVR). Cette suppression de pratiques courantes comme l’apprentissage par renforcement avec rétroaction humaine (RLHF) ajoute de l’efficacité au processus de formation, mais supprime une autre interaction homme-machine où les préférences humaines peuvent être transférées directement au système en cours de formation.
Évolution continue des modèles d'IA après la formation
Certains agents d’IA évoluent constamment et leur comportement peut changer après le déploiement. Une fois que les solutions d’IA entrent dans un environnement de déploiement, comme la gestion des stocks ou la chaîne d’approvisionnement d’une entreprise, le système s’adapte et apprend de l’expérience pour devenir plus efficace. Il s’agit d’un facteur clé pour repenser l’alignement, car il ne suffit pas d’avoir un système aligné dès le premier déploiement. Les modèles de langage de grande taille (LLM) actuels ne devraient pas évoluer et s’adapter de manière significative une fois déployés dans leur environnement cible. Cependant, les agents d’IA nécessitent une formation flexible, un réglage précis et un mentorat continu pour gérer ces changements prévisibles et continus dans le modèle. Dans une mesure croissante, l’IA des agents évolue d’elle-même plutôt que d’être façonnée par les personnes à travers la formation et l’exposition à des ensembles de données. Ce changement fondamental pose des défis supplémentaires pour aligner l’IA avec ses créateurs humains.
Bien que l'évolution basée sur l'apprentissage par renforcement joue un rôle lors de l'entraînement et du réglage fin, les modèles en développement peuvent déjà ajuster leurs pondérations et leur plan d'action privilégié lors de leur déploiement sur le terrain pour l'inférence. Par exemple, DeepSeek-R1 utilise l'apprentissage par renforcement (RL), qui permet au modèle d'explorer lui-même les approches les plus performantes pour obtenir des résultats et satisfaire aux fonctions de récompense. Lors d'un « moment de prise de conscience », le modèle apprend (sans aide ni incitation) à allouer un temps de réflexion supplémentaire à la résolution d'un problème en réévaluant son approche initiale, en utilisant Calcul du temps de test.
Le concept d'apprentissage d'un modèle, soit sur une période de temps limitée, soit sous forme de apprentissage tout au long de la vie, pas nouveau. Cependant, des développements sont en cours dans ce domaine, notamment des technologies telles que : Entraînement au moment du test. Si nous considérons ces progrès du point de vue de l’alignement et de la sécurité de l’IA, l’auto-modification et l’apprentissage continu pendant les phases de réglage fin et de raisonnement soulèvent la question suivante : comment pouvons-nous inculquer un ensemble d’exigences qui continueront à piloter le modèle à travers les changements physiques résultant des auto-modifications ?
Une variante importante de cette question fait référence aux modèles d’IA qui créent des modèles de nouvelle génération en générant du code à l’aide de l’IA. Dans une certaine mesure, les agents sont déjà capables de créer de nouveaux modèles d’IA ciblés pour répondre à des domaines spécifiques. Par exemple, il le fait Agents automatiques Créez plusieurs agents pour constituer une équipe d’IA afin d’effectuer différentes tâches. Il ne fait aucun doute que cette capacité sera améliorée dans les mois et les années à venir, et que l’IA créera de nouvelles IA. Dans ce scénario, comment guider l’assistant de codage IA natif à l’aide d’un ensemble de principes afin que ses modèles « atomiques » soient conformes aux mêmes principes à une profondeur similaire ?
Points clés
Avant de se plonger dans un cadre pour guider et surveiller la conformité de l’IA, une compréhension plus approfondie de la manière dont les agents d’IA pensent et prennent des décisions est essentielle. Les agents IA ont des mécanismes comportementaux complexes, motivés par des motivations internes. Les systèmes d’IA qui fonctionnent comme des agents rationnels présentent cinq principaux types de comportements : Volonté de survie, protection des buts, augmentation du renseignement, accumulation de ressources et tromperie tactique. Ces motivations doivent être équilibrées par un ensemble solide de principes et de valeurs.
Un mauvais alignement des objectifs et des méthodes des agents d’IA avec leurs développeurs ou utilisateurs peut avoir des impacts significatifs. Le manque de confiance et d’assurance suffisants entravera considérablement le déploiement à grande échelle, créant des risques élevés après le déploiement. L’ensemble des défis que nous décrivons comme une planification approfondie est sans précédent et difficile, mais ils peuvent potentiellement être résolus avec le bon cadre. Les technologies permettant de diriger et de surveiller les agents d’IA doivent être développées en priorité, car elles évoluent rapidement. Il existe un sentiment d’urgence, motivé par des indicateurs d’évaluation des risques tels que : Cadre de préparation d'OpenAI Ce qui montre que l'OpenAI o3-mini est le premier modèle qui Atteint un niveau de risque moyen en termes d'indépendance du modèle.
Dans les prochains blogs de cette série, nous nous appuierons sur cette vision de la motivation interne et de la planification approfondie, en définissant plus précisément les capacités nécessaires requises pour l’orientation et la surveillance de la conformité du cœur de l’IA.
- Apprendre à raisonner avec les LLM. (2024, 12 septembre). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025, 4 mars). Le besoin urgent de technologies d'alignement intrinsèque pour une IA agentique responsable. Vers la science des données. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Sur la biologie d'un grand modèle de langage. (sd). Circuits de transformateur. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, FL, Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., . . . Zoph, B. (2023, 15 mars). Rapport technique GPT-4. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (sd). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R. et Hobbhahn, M. (2024 décembre 6). Les modèles Frontier sont capables de concevoir des schémas en contexte. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Les lecteurs d'IA de base. Systèmes auto-conscients. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., et Soares, N., UC Berkeley, Institut de recherche sur l'intelligence artificielle. (sd). Formaliser les objectifs instrumentaux convergents. Les ateliers de la trentième conférence de l'AAAI sur Intelligence Artificielle IA, éthique et société : rapport technique WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, SR et Hubinger, E. (2024 décembre 18). Simulation d'alignement dans les grands modèles de langage. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F., et Ward, F.R. (2024, 11 juin). IA Sandbagging : les modèles linguistiques peuvent stratégiquement sous-performer lors des évaluations. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, DM, Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, 10 janvier). Agents dormants : formation de LLM trompeurs qui persistent grâce à la formation à la sécurité. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., et Tadepalli, P. (2019 décembre 3). Les politiques optimales ont tendance à rechercher le pouvoir. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Tout ce que j’ai vraiment besoin de savoir, je l’ai appris à la maternelle. Penguin Random House Canada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, juin). Apprentissage du curriculum. Journal de l'Association américaine de podologie. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025, 22 janvier). DeepSeek-R1 : Stimuler la capacité de raisonnement dans les LLM grâce à l'apprentissage par renforcement. arXiv.org. https://arxiv.org/abs/2501.12948
- Mise à l'échelle du temps de calcul des tests – un espace Hugging Face par HuggingFaceH4. (nd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., et Hardt, M. (2019 septembre 29). Entraînement au temps de test avec auto-supervision pour la généralisation sous changements de distribution. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, BF, Fu, J. et Shi, Y. (2023, 29 septembre). AutoAgents : un framework pour la génération automatique d'agents. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, 18 décembre). Cadre de préparation (version bêta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Carte système OpenAI o3-mini. (sd). OpenAI. https://openai.com/index/o3-mini-system-card
Les commentaires sont fermés.