

Atteindre la certitude dans les grands modèles de langage (LLM) en utilisant des circuits de prise de décision intelligents
L’incertitude n’est pas une nouveauté dans le domaine technologique : tous les systèmes modernes surmontent les entrées et les sorties incertaines en utilisant des structures de contrôle mathématiquement prouvées.
La promesse des agents IA a pris le monde d’assaut. Les agents peuvent interagir avec le monde qui les entoure, écrire des articles (mais pas celui-ci), prendre des mesures en votre nom et, de manière générale, rendre la partie difficile de l'automatisation de toute tâche facile et accessible.
Les agents ciblent les parties les plus difficiles des opérations et résolvent les problèmes rapidement. Parfois trop rapidement – Si votre processus basé sur des agents nécessite l’intervention d’un humain pour décider du résultat, l’étape de révision humaine peut devenir un goulot d’étranglement dans le processus.
Un exemple de processus basé sur un agent est le traitement et la classification des appels téléphoniques des clients. Même un agent avec une précision de 99.95 % fera 5 erreurs en écoutant 10,000 XNUMX appels. Même si l'agent le sait, il ne peut pas vous le dire. أي 5 appels sur 10,000 XNUMX ont été mal classés.

La technique « LLM-as-a-Judge » est une technique dans laquelle vous introduisez chaque entrée dans un autre processus LLM pour évaluer si la sortie provenant de l'entrée est correcte. Cependant, comme il s’agit d’un autre processus LLM, il peut également être inexact. Ces deux opérations probabilistes créent une matrice de confusion avec des vrais positifs, des faux négatifs, des vrais négatifs et des faux positifs.
En d’autres termes, une entrée correctement classée par un processus LLM peut être jugée incorrecte par son juge LLM ou vice versa.
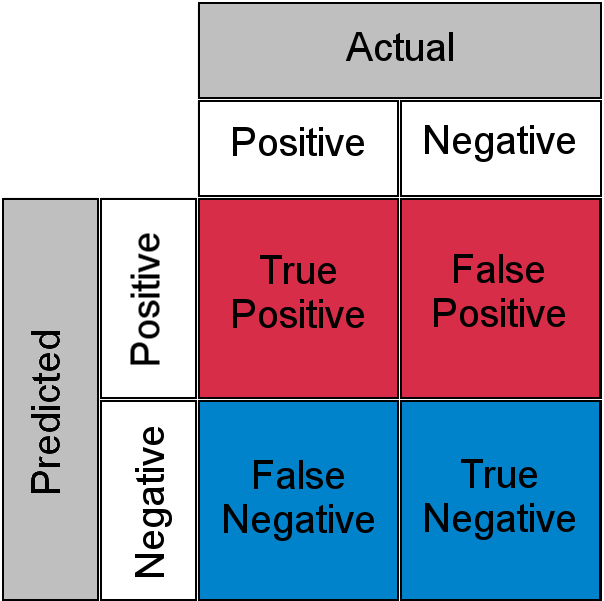
à cause de ça " L'inconnu connu Pour une charge de travail sensible, un humain doit examiner et comprendre les 10,000 XNUMX appels. On se retrouve avec le même problème de goulot d'étranglement.
Comment pouvons-nous renforcer la certitude statistique de nos processus pilotés par agents ? Dans cet article, je construis un système qui nous permet d'accroître la certitude de nos processus pilotés par agents, je le généralise à un nombre arbitraire d'agents et je développe une fonction de coût pour guider les investissements futurs dans le système. Le code que j'utilise dans cet article est disponible dans mon dépôt. circuits de décision d'IA.
Circuits de prise de décision de l'IA
Détecter et corriger les erreurs ne sont pas des concepts nouveaux. La correction des erreurs est cruciale dans des domaines tels que l’électronique numérique et analogique. Même les progrès de l’informatique quantique dépendent de l’expansion des capacités de correction et de détection des erreurs. Nous pouvons nous inspirer de ces systèmes et mettre en œuvre quelque chose de similaire avec des agents IA. Par exemple, vous pouvez Algorithmes d'intelligence artificielle Utilisation avancée des techniques de correction d’erreurs trouvées dans les systèmes de communication.
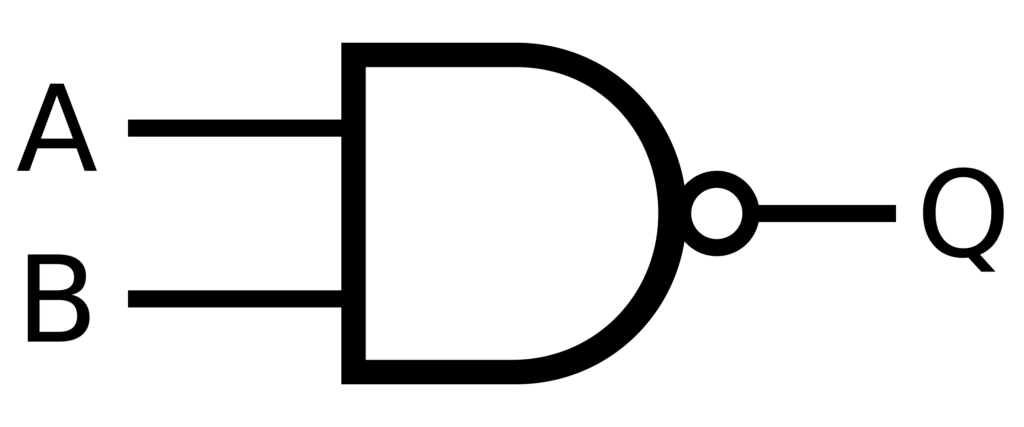
Dans la logique booléenne, les portes NAND sont le Saint Graal du calcul car elles peuvent effectuer n'importe quelle opération. Il est fonctionnellement complet, ce qui signifie que toute opération logique peut être créée en utilisant uniquement des portes NAND. Ce principe peut être appliqué aux systèmes d’IA pour créer des structures de prise de décision robustes avec correction d’erreurs intégrée. Cela permet la création de réseaux neuronaux Plus fiable et capable de gérer des données incomplètes ou bruyantes.
Des circuits électroniques aux circuits de prise de décision intelligente (IA)
Tout comme les circuits électroniques utilisent la répétition et la vérification pour garantir des calculs fiables, les circuits de prise de décision intelligente (IA) peuvent utiliser plusieurs agents avec des perspectives différentes pour arriver à des résultats plus précis. Ces circuits peuvent être construits en utilisant les principes de la théorie de l’information et de la logique booléenne :
- Traitement redondant : Plusieurs agents d’IA traitent les mêmes entrées de manière indépendante, de la même manière que les processeurs modernes utilisent des circuits redondants pour détecter les erreurs matérielles. Ce processus augmente la fiabilité du système d’IA.
- Mécanismes de consensus : Les sorties de décision sont combinées à l'aide de systèmes de vote ou de moyennes pondérées, similaires aux portes logiques majoritaires dans l'électronique tolérante aux pannes. Ces mécanismes garantissent que la décision finale reflète le consensus entre les agents.
- Agents validateurs : Les auditeurs d'IA spécialisés vérifient le caractère raisonnable de la sortie, fonctionnant de manière similaire aux codes de détection d'erreurs tels que Bits de parité ou contrôles de redondance cyclique (contrôles CRC). Ces agents réduisent la probabilité de prendre de mauvaises décisions.
- Intégration humaine dans la boucle : Vérification humaine stratégique à des moments clés du processus de prise de décision, de la même manière que les systèmes biométriques utilisent la surveillance humaine comme couche de vérification finale. Cela garantit que les décisions importantes sont soumises à une évaluation humaine.
Fondements mathématiques des circuits de décision en intelligence artificielle
La fiabilité de ces systèmes peut être déterminée quantitativement à l’aide de la théorie des probabilités.
D'une part, la probabilité d'échec provient de la précision observée au fil du temps sur un ensemble de données de test, stocké dans un système tel que LangSmith.

Pour un facteur précis à 90 %, la probabilité d'échec, p_1، 1–0.9 C'est 0.1, soit 10 %.

La probabilité que deux facteurs indépendants échouent sur la même entrée est la probabilité que les deux facteurs soient précis multipliée ensemble :
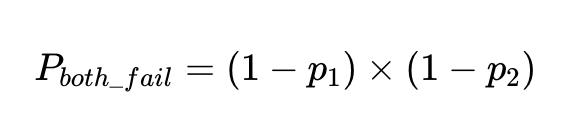
Si nous avons N exécutions avec ces clients, le nombre total d'échecs est
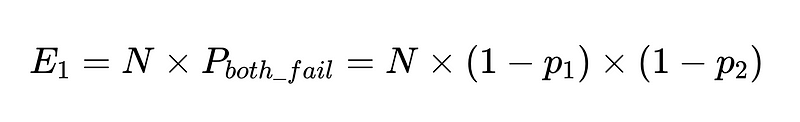
Ainsi, pour 10,000 90 exécutions entre deux travailleurs indépendants avec une précision de 100 %, le nombre d’échecs attendu est de XNUMX.
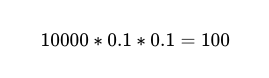
Cependant, nous ne le savons toujours pas. أي Sur ces 10,000 100 appels téléphoniques, XNUMX sont de véritables échecs.
Nous pouvons combiner quatre extensions de cette idée pour fournir une solution plus robuste qui offre une confiance dans toute réponse donnée :
- Classificateur de base (résolution simple ci-dessus)
- Sauvegarde (résolution simple ci-dessus)
- Vérificateur de schéma (résolution 0.7 par exemple)

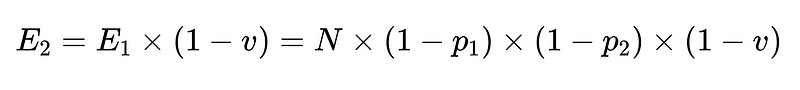
- Enfin, un validateur négatif (n = précision 0.6 par exemple)
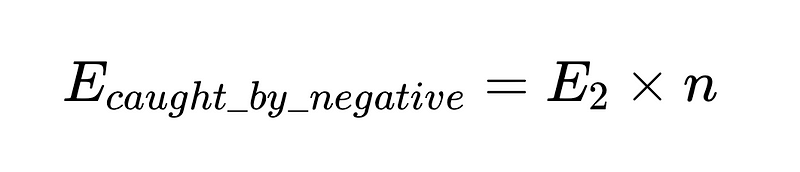
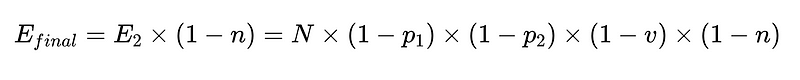
Pour mettre cela dans le code (L'entrepôt complet), nous pouvons utiliser Python basique:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESEn combinant ces opérations avec la logique, Boolean En termes simples, nous pouvons obtenir une précision et une confiance similaires dans chaque réponse :
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Logique de décision : une explication étape par étape
Étape 1 : Lorsque le système de contrôle qualité échoue
if not validation_result:Cela signifie : « Si notre expert en contrôle qualité (auditeur) rejette l’analyse initiale, ne lui faites pas confiance. » Le système essaie alors d'utiliser l'avis de sauvegarde à la place. Si cette vérification échoue également, le cas est signalé pour examen par un spécialiste humain. Cette procédure garantit que vous ne vous fiez pas à des données inexactes.
En termes simples : « Si notre première réponse est erronée, essayons notre méthode de secours. Si le doute persiste, demandons l'intervention d'un expert. » Cela garantit que les cas complexes sont traités correctement.
Étape 2 : Corriger les divergences
if negative_check == 'no' and primary_result['call_type'] is not None:Cette étape vérifie un type spécifique d’écart : « Notre vérificateur négatif indique qu’il ne devrait pas y avoir de type d’appel, mais notre analyste fondamental a quand même trouvé un type de vente. »
Dans de tels cas, le système s'appuie sur l'analyste de secours pour atteindre le seuil de rentabilité :
- Si l'analyste de sauvegarde convient qu'il n'y a pas de type d'appel, il est envoyé à l'élément humain.
- Si l’analyste de secours est d’accord avec l’analyste principal, alors l’analyse est acceptée, mais avec une confiance moyenne.
- Si l'analyste de sauvegarde a un type d'appel différent ← il est envoyé à l'élément humain
C’est comme dire : « Si un expert dit que c’est inclassable mais qu’un autre dit que c’est le cas, nous avons besoin d’un départageur ou d’un juge humain. » Ce mécanisme est nécessaire pour garantir une classification précise des types d’appels et réduire les erreurs potentielles.
Étape 3 : Lorsque les experts sont d’accord
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Lorsque les analystes principaux et de secours parviennent indépendamment à la même conclusion, le système la marque comme « haute confiance » ; c'est le meilleur scénario. Cette situation idéale se produit lorsque plusieurs analyses sont concluantes et cohérentes.
En termes simples : « Si deux experts différents utilisant des méthodes différentes parviennent indépendamment à la même conclusion, nous pouvons être assez sûrs que leur conclusion est correcte. » Cela représente le consensus des experts, ce qui est un indicateur fort de précision et de fiabilité.
Étape 4 : Traitement par défaut
Si aucune des conditions spéciales ne s'applique, le système utilise par défaut le résultat de l'analyste principal avec une confiance « moyenne ». Si l’analyste principal n’est pas en mesure d’identifier le type d’appel, il signale le cas pour qu’il soit examiné par un analyste humain spécialisé.
L’importance de cette approche dans la réduction des erreurs
Cette logique contribue à construire un système solide en :
- Réduire les faux positifsLe système n'offre une grande confiance que lorsque plusieurs méthodes concordent, ce qui réduit considérablement les fausses alarmes.
- Découvrir les contradictionsLorsque différentes parties du système diffèrent, cela réduit la confiance ou transmet le problème à des examinateurs humains, garantissant ainsi qu'aucun problème potentiel ne soit négligé.
- Escalade intelligenteLes examinateurs humains ne voient que les cas qui nécessitent réellement leur expertise, ce qui augmente l’efficacité du processus d’examen et réduit le stress des ressources humaines.
- Désignation de fiducieLes résultats incluent le niveau de confiance du système, permettant aux processus ultérieurs de traiter différemment les résultats à haute confiance et ceux à confiance moyenne, ce qui est essentiel pour prendre des décisions éclairées.
Cette approche est similaire à la façon dont l’électronique utilise des circuits redondants et des mécanismes de vote pour empêcher les erreurs de provoquer une défaillance du système. Dans les systèmes d’IA, ce type de logique d’intégration réfléchie peut réduire considérablement les taux d’erreur tout en utilisant efficacement les réviseurs humains uniquement là où ils ajoutent le plus de valeur. Cela garantit que les ressources sont optimisées et que les erreurs sont réduites simultanément, ce qui donne un système plus fiable et plus précis.
مثال
En 2015, le département des eaux de la ville de Philadelphie a publié Statistiques des appels clients par catégorie. Comprendre les appels des clients est un processus très courant auquel les agents sont confrontés. Au lieu de demander à un humain d’écouter chaque appel téléphonique d’un client, un agent peut écouter l’appel beaucoup plus rapidement, extraire des informations et catégoriser l’appel pour une analyse plus approfondie des données. Pour la gestion de l’eau, cela est important car plus tôt les problèmes critiques sont identifiés, plus tôt ils peuvent être résolus.
Nous pouvons construire une expérience. J'ai utilisé un grand modèle de langage (LLM) pour générer de fausses transcriptions des appels téléphoniques en question en demandant : « Étant donné la classe suivante, générez une version courte de cet appel téléphonique : Voici quelques-uns de ces exemples avec le fichier complet disponible. ici:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Maintenant, nous pouvons mettre en place l'expérience avec une évaluation plus traditionnelle en utilisant un grand modèle de langage comme juge (Mise en œuvre complète ici):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeEn transmettant uniquement le texte à un grand modèle de langage (LLM), nous pouvons isoler la véritable connaissance de classe de la classe extraite qui est renvoyée et comparer.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultL'exécution de cette méthode sur l'ensemble des données synthétiques à l'aide de Claude 3.7 Sonnet (le dernier modèle, au moment de la rédaction de cet article) est très performante, 91 % des appels étant classés avec précision :
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}S’il s’agissait d’appels réels et que nous n’avions aucune connaissance préalable de la catégorie, nous devrions quand même examiner les 100 appels téléphoniques pour trouver les 9 appels mal classés.
En appliquant notre puissant circuit de prise de décision ci-dessus, nous obtenons des résultats de précision similaires avec Confiance Dans ces réponses. Dans ce cas, une précision globale de 87% mais une précision de 92.5% dans nos réponses à haute confiance.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Nous avons besoin d’une précision de 100 % dans nos réponses de haute confiance, il reste donc encore du travail à faire. Ce que cette approche nous permet de faire, c'est d'approfondir Raison Inexactitude des réponses de haute confiance. Dans ce cas, les revendications faibles et les capacités de vérification simples ne permettent pas de saisir tous les problèmes, ce qui entraîne des erreurs de classification. Ces capacités peuvent être améliorées de manière itérative pour atteindre une précision de 100 % sur des réponses de haute confiance.
Améliorations du système de filtrage pour augmenter la confiance dans les résultats.
Le système actuel classe les réponses comme étant « hautement fiables » lorsque les analystes principaux et de secours sont d’accord. Pour obtenir une plus grande précision, nous devons être plus sélectifs quant à ce qui est considéré comme une « confiance élevée ».
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}En ajoutant des critères de qualification supplémentaires, nous obtiendrons moins de résultats « de haute confiance », mais ils seront plus précis. Cette amélioration du système de filtrage vise à réduire les erreurs et à augmenter la fiabilité des données classées comme de haute qualité.
Techniques de vérification supplémentaires : améliorer la précision de l'analyse
Voici quelques autres idées pour améliorer votre processus de validation et d’analyse des données :
Analyseur tertiaireAjoutez une troisième méthode d’analyse indépendante. Cette méthode sert de couche supplémentaire de vérification, en comparant les résultats de deux méthodes analytiques différentes avec le résultat d’une troisième méthode, pour garantir une plus grande précision et réduire la possibilité d’erreurs.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Correspondance de modèles historiques:Comparez les résultats avec les résultats historiquement corrects (pensez à la recherche vectorielle). Cette technique utilise des données historiques fiables comme référence et compare les résultats actuels à celles-ci pour identifier les écarts ou les incohérences. On peut le considérer comme une sorte de « mémoire » d’analyse, aidant à détecter des anomalies ou des situations inattendues.
if similarity_to_known_correct_cases(primary_result) > 0.95:Tests contradictoiresAppliquez de petites variations aux entrées et vérifiez si la classification reste stable. Cette méthode vise à tester la robustesse et la robustesse d'un système de classification en l'exposant à des modifications mineures dans les données. Si le système est très sensible à ces changements, cela peut indiquer des faiblesses ou des biais potentiels.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Formule générale pour les interventions humaines dans un système d'extraction LLM
La dérivation complète est disponible ici..
- N = Nombre total d'exécutions (10,000 XNUMX dans notre exemple)
- p_1 = précision de l'analyseur de base (0.8 dans notre exemple)
- p_2 = précision de l'analyseur de secours (0.8 dans notre exemple)
- v = efficacité du validateur de schéma (0.7 dans notre exemple)
- n = efficacité du vérificateur négatif (0.6 dans notre exemple)
- H = nombre d'interventions humaines nécessaires
- E_final = erreurs finales non détectées
- m = nombre d'auditeurs indépendants
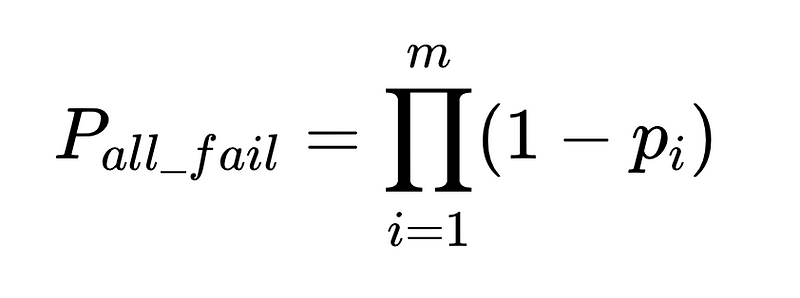
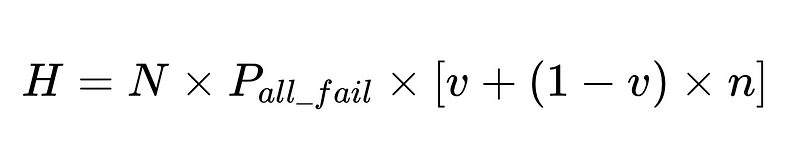
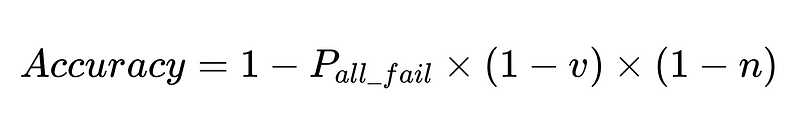
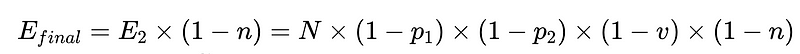
Conception optimale du système
L'équation révèle des informations clés sur la précision d'un système de traitement du langage naturel (TALN) :
- L'ajout d'analyseurs réduit la surcharge mais améliore la précision globale.
- La précision du système est limitée par :
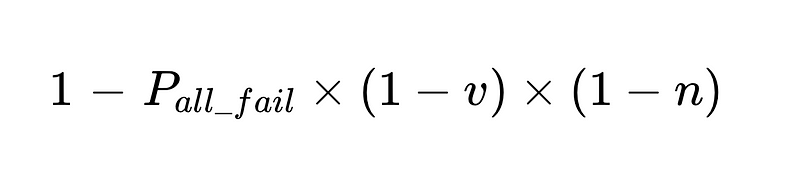
- Les interventions humaines sont proportionnelles Directement Avec un total de N exécutions.
Par exemple:
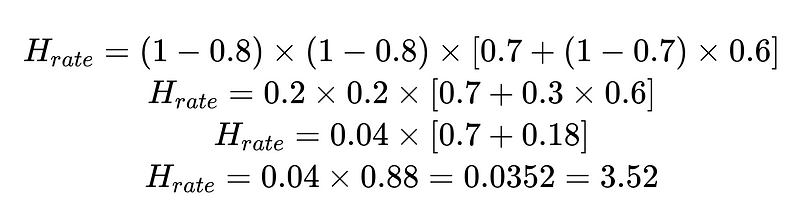
Nous pouvons utiliser le taux d’intervention humaine calculé (H_rate) pour suivre l’efficacité de notre solution en temps réel. Si le taux d’intervention humaine commence à dépasser 3.5 %, nous savons que le système est en train de défaillir. Si le taux d’intervention humaine diminue systématiquement à moins de 3.5 %, nous savons que nos optimisations fonctionnent comme prévu.
fonction de coût
Nous pouvons également créer une fonction de coût qui nous aide à améliorer notre système. La fonction de coût est un outil d’analyse puissant permettant d’évaluer les performances financières d’un système et d’identifier les domaines potentiels d’amélioration.
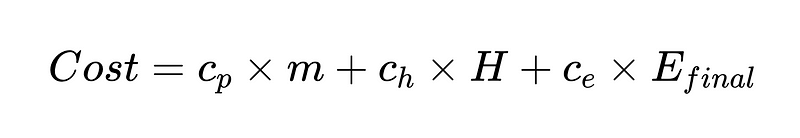
Nom:
- c_p = coût de fonctionnement par analyseur (0.10 $ dans notre exemple)
- m = nombre de fois que l'analyseur est exécuté (dans notre exemple 2 * N)
- H = Nombre de cas nécessitant une intervention humaine (352 dans notre exemple)
- c_h = coût d'une intervention humaine (200 $ par exemple : 4 heures à 50 $/heure)
- c_e = coût d'une erreur non détectée (par exemple, 1000 XNUMX $)
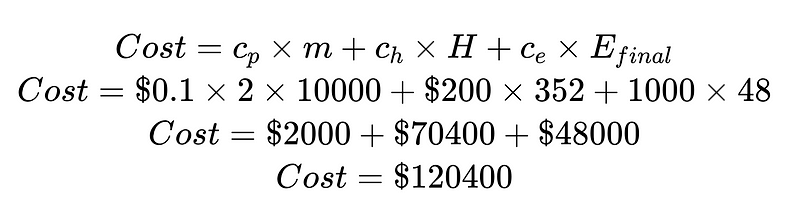
En divisant le coût par le coût de l'intervention humaine et le coût des erreurs non détectées, nous pouvons améliorer le système global. Dans cet exemple, si le coût de l'intervention humaine (70,400 48,000 $) est indésirable et coûteux, nous pouvons nous concentrer sur l'amélioration des résultats de haute fiabilité. Si le coût des erreurs non détectées (XNUMX XNUMX $) est indésirable et coûteux, nous pouvons introduire des analyseurs de syntaxe Plus pour réduire le taux d'erreurs non détectées.
Bien sûr, les fonctions de coût sont particulièrement utiles pour explorer comment améliorer les situations qu’elles décrivent.
À partir du scénario ci-dessus, pour réduire le nombre d'erreurs non détectées, E_final, de 50 %, où
- p1 et p2 = 0.8,
- v = 0.7 et
- n = 0.6
Nous avons trois options :
- Un nouvel analyseur grammatical avec une précision de 50 % a été ajouté comme analyseur secondaire. Notez que cela implique un compromis : le coût d'exploitation des analyseurs grammaticaux Plus augmente avec le coût de l'intervention humaine.
- Améliorez les analyseurs grammaticaux existants de 10 % chacun. Cela peut être possible ou non en raison de la difficulté de la tâche effectuée par ces analyseurs syntaxiques.
- Améliorer le processus d’audit de 15 %. Encore une fois, cela augmente le coût en raison de l’intervention humaine.
L'avenir de la confiance en IA : instaurer la confiance grâce à une précision extrême
À mesure que les systèmes d’IA s’intègrent de plus en plus dans des aspects vitaux des entreprises et de la société, la recherche d’une précision optimale deviendra de plus en plus impérative, en particulier dans les applications critiques. En adoptant ces approches inspirées des circuits pour la prise de décision en matière d’IA, nous pouvons créer des systèmes qui non seulement évoluent efficacement, mais qui gagnent également la confiance profonde qui ne vient que de performances cohérentes et fiables. L’avenir ne réside pas dans des modèles individuels plus puissants, mais dans des systèmes soigneusement conçus qui combinent des perspectives multiples avec une supervision humaine stratégique.
Tout comme l’électronique numérique a évolué à partir de composants peu fiables pour créer des ordinateurs auxquels nous confions nos données les plus importantes, les systèmes d’IA suivent désormais un parcours similaire. Les cadres décrits dans cet article représentent les plans de ce qui deviendra à terme l’architecture standard de l’IA critique : des systèmes qui non seulement promettent la fiabilité, mais la garantissent mathématiquement. La question n’est plus de savoir si nous pouvons construire des systèmes d’IA avec une précision quasi parfaite, mais de savoir à quelle vitesse nous pouvons mettre en œuvre ces principes dans nos applications les plus importantes.
Les commentaires sont fermés.