

Évaluation des performances des modèles distillés DeepSeek-R1 sur GPQA à l'aide d'Ollama et de simples évaluations d'OpenAI
Configurez et exécutez le benchmark GPQA-Diamond sur des modèles DeepSeek-R1 distillés localement pour évaluer leurs capacités d'inférence.
Lancement du dernier modèle DeepSeek-R1 Largement résonné dans la communauté mondiale de l’IA. Il a réalisé des avancées comparables aux modèles d’inférence de Meta et d’OpenAI, et ce en une fraction du temps et à un coût bien inférieur.
Mais au-delà des gros titres et du battage médiatique en ligne, comment pouvons-nous évaluer les capacités d’inférence d’un modèle à l’aide de critères reconnus ? C’est une question importante pour les experts en IA.
. Interface utilisateur Recherche profonde Il facilite l'exploration de ses capacités, mais son utilisation par programmation fournit des informations plus approfondies et une intégration plus fluide dans les applications du monde réel. Comprendre comment ces modèles fonctionnent localement permet également d’améliorer le contrôle et l’accès hors ligne.

Dans cet article, nous allons explorer comment utiliser Ollama et évaluations simples d'OpenAI Évaluer les capacités d'inférence des modèles distillés DeepSeek-R1 basés sur le benchmark GPQA-Diamant Célèbre. Ce critère est considéré comme l’un des outils les plus importants pour évaluer les modèles d’intelligence artificielle dans le domaine du raisonnement logique.
ici Lien vers le dépôt GitHub Accompagnant cet article.
(1) Quels sont les modèles de raisonnement ?
Les modèles d'inférence, tels que DeepSeek-R1 et les modèles de la série o d'OpenAI (par exemple, o1, o3), sont des modèles de langage de grande taille (LLM) formés à l'aide de l'apprentissage par renforcement pour effectuer des inférences. Ces modèles sont des outils avancés dans le domaine de l’intelligence artificielle, représentant le summum de l’évolution dans la capacité des machines à penser logiquement et à résoudre des problèmes complexes.
Les heuristiques se caractérisent par une réflexion approfondie avant de répondre, produisant une longue série de pensées internes avant de répondre. Il excelle dans la résolution de problèmes complexes, la programmation, le raisonnement scientifique et la planification en plusieurs étapes des flux de travail des agents. Ces capacités les rendent indispensables dans des domaines tels que le développement de logiciels avancés, la recherche scientifique et l’automatisation de processus complexes.
(2) Qu'est-ce que le modèle DeepSeek-R1 ?
DeepSeek-R1 est un modèle de langage étendu (LLM) open source de pointe, spécialement conçu pour Raisonnement avancé. Soumis en janvier 2025 dans le document de recherche "DeepSeek-R1 : Optimiser la puissance d'inférence dans les grands modèles linguistiques grâce à l'apprentissage par renforcement". DeepSeek-R1 est un modèle pionnier dans le domaine de l'intelligence artificielle.
Ce modèle est basé sur une architecture de modèle de langage de grande taille (LLM) avec 671 milliards de paramètres et a été formé à l'aide d'un apprentissage par renforcement (RL) extensif basé sur le chemin suivant :
- Deux étapes d’augmentation visent à découvrir des modèles de raisonnement améliorés et à s’aligner sur les préférences humaines.
- Deux étapes de réglage fin supervisé servent de base aux capacités d’inférence et de non-inférence du modèle.
Pour illustrer, DeepSeek a formé deux modèles :
- Le premier modèle, DeepSeek-R1-Zéro, est un modèle d'inférence formé à l'aide de l'apprentissage par renforcement, et génère des données pour former le deuxième modèle, DeepSeek-R1.
- Il y parvient en produisant des traces d’inférence, dont seules les sorties de haute qualité sont conservées en fonction de leurs résultats finaux.
- Cela signifie que contrairement à la plupart des modèles, les exemples d’apprentissage par renforcement (RL) de ce pipeline de formation ne sont pas organisés par des humains mais sont générés par le modèle lui-même.
Le résultat est que le modèle a obtenu des performances similaires à celles des principaux modèles tels que Modèle o1 d'OpenAI Dans des tâches telles que les mathématiques, la programmation et le raisonnement complexe.
(3) Comprendre le processus de distillation et les modèles distillés de DeepSeek-R1
En plus du modèle complet, ils ont également ouvert le code source de six modèles denses plus petits (également appelés DeepSeek-R1) de différentes tailles (1.5B, 7B, 8B, 14B, 32B, 70B), distillés à partir de DeepSeek-R1 sur la base de Qwen ou Flamme Comme modèle de base.
Distillation Il s’agit d’une technique dans laquelle un modèle plus petit (« étudiant ») est formé pour reproduire les performances d’un modèle plus grand et plus puissant qui a été préalablement formé (« enseignant »).
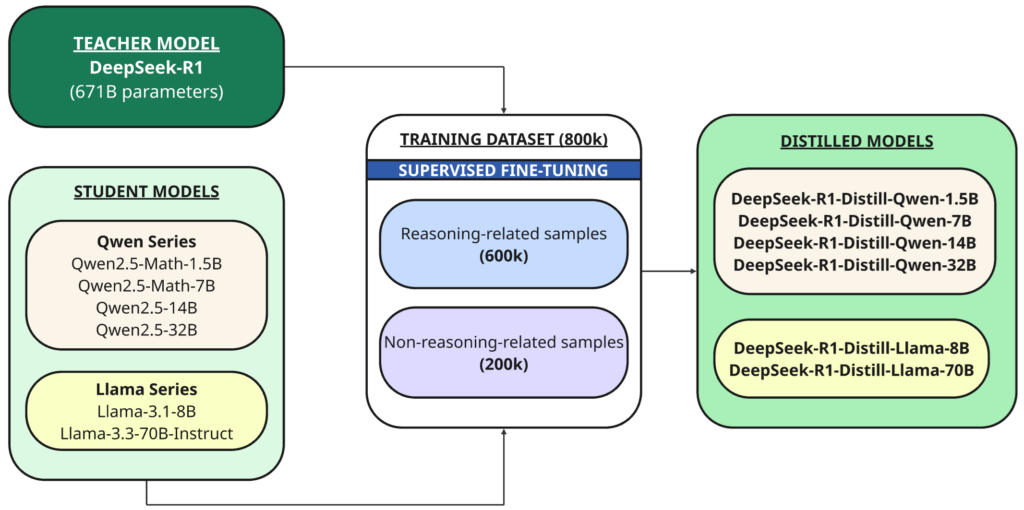
Dans ce cas, l'enseignant est le modèle 1B DeepSeek-R671, et les étudiants sont les six modèles distillés à l'aide de ce modèle de base open source :
- Qwen2.5 — Math-1.5B
- Qwen2.5 — Math-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lama-3.1 — 8B
- Lama-3.3 — 70B-Instruct
DeepSeek-R1 a été utilisé comme modèle d'enseignant pour générer 800,000 XNUMX échantillons d'entraînement, un mélange d'échantillons d'inférence et de non-inférence, pour la distillation à travers réglage fin supervisé Pour les modèles de base (1.5B, 7B, 8B, 14B, 32B et 70B).
Alors, pourquoi distillons-nous en premier lieu ?
L’objectif est de transférer les capacités d’inférence de modèles plus grands, tels que DeepSeek-R1 671B, vers des modèles plus petits et plus efficaces. Cela permet aux modèles plus petits de gérer des tâches d'inférence complexes tout en étant plus rapides et plus économes en ressources.
De plus, DeepSeek-R1 possède un nombre considérable de paramètres (671 milliards), ce qui rend son exécution difficile sur la plupart des appareils grand public.
Même le MacBook Pro le plus puissant, avec une mémoire unifiée maximale de 128 Go, ne suffit pas à faire fonctionner un modèle avec des paramètres de 671 milliards.
Ainsi, les modèles distillés ouvrent la possibilité de les déployer sur des appareils dotés de ressources de calcul limitées.
Atteint Insouciant Une réalisation remarquable en quantifiant le modèle DeepSeek-R1 original de 671 milliards de paramètres à seulement 131 Go, soit une réduction remarquable de 80 % de la taille. Cependant, l’exigence de 131 Go de VRAM reste un obstacle important, en particulier pour les développeurs travaillant sur des appareils aux ressources limitées. Cette réalisation représente une étape importante vers l’accessibilité des grands modèles d’IA à un plus large éventail d’utilisateurs.
(4) Sélection du modèle distillé optimal
Avec six tailles différentes de modèles distillés parmi lesquels choisir, déterminer le bon modèle dépend en grande partie des capacités de votre équipement local.
Pour ceux qui disposent de GPU ou de CPU hautes performances et qui ont besoin de performances maximales, les modèles DeepSeek-R1 plus grands (32 B et plus) sont idéaux – même la version quantique 671 B est viable.
Cependant, si les ressources sont limitées ou si vous préférez des temps de construction plus rapides (comme moi), des variantes distillées plus petites, telles que 8B ou 14B, sont une meilleure option. Cela permet d’équilibrer les performances et les besoins en ressources.
Pour ce projet, j'utiliserai le modèle DeepSeek-R1 distillé. Qwen-14B, qui correspond aux limitations matérielles que vous avez rencontrées. Ce modèle (14B) représente un excellent compromis entre précision et rapidité, ce qui en fait un modèle parfaitement adapté à mon environnement de développement.
(5) Critères d'évaluation de la capacité d'inférence des grands modèles de langage
Les grands modèles de langage (LLM) sont généralement évalués à l’aide de mesures standardisées qui déterminent leurs performances sur diverses tâches, notamment la compréhension du langage, la génération de code, le suivi des instructions et la réponse aux questions. Des exemples courants incluent des mesures telles que : MMLU, et HumanEval, et MGSM. Ces mesures sont essentielles pour évaluer les capacités des grands modèles linguistiques.
Pour mesurer la capacité d’un grand modèle de langage à raisonner, nous avons besoin de critères de référence plus ambitieux qui se concentrent fortement sur le raisonnement et vont au-delà des tâches superficielles. Voici quelques exemples courants qui se concentrent sur l’évaluation des capacités de raisonnement avancées :
(i) Examen AIME 2024 : Mathématiques compétitives
- Préparer Examen américain de mathématiques sur invitation (AIME) 2024 Une référence robuste pour évaluer les capacités des grands modèles de langage (LLM) dans le raisonnement mathématique.
- Cet examen représente un défi important en mathématiques compétitives, car il présente des problèmes complexes en plusieurs étapes. L'examen teste la capacité des grands modèles linguistiques à comprendre des questions complexes, à appliquer un raisonnement avancé et à effectuer des manipulations symboliques précises. L'AIME est une mesure importante pour évaluer les compétences en résolution de problèmes mathématiques complexes.
(ii) Codeforces – Code de la concurrence
- Le Norme Codeforces Évaluation de la capacité d'inférence d'un grand modèle de langage (LLM) à l'aide de problèmes de programmation compétitifs du monde réel de Codeforces, une plate-forme connue pour ses défis algorithmiques. Codeforces est la référence absolue pour évaluer les capacités des modèles d’IA à résoudre des problèmes complexes.
- Ces problèmes testent la capacité d'un grand modèle de langage (LLM) à comprendre des instructions complexes, à effectuer un raisonnement logique et mathématique, à planifier des solutions en plusieurs étapes et à générer un code correct et efficace. Ces problèmes nécessitent une compréhension approfondie des algorithmes et des structures de données, ainsi que la capacité de traduire le problème en code exécutable.
(iii) GPQA Diamond – Questions scientifiques de niveau doctorat
- GPQA-Diamond est un sous-ensemble sélectionné de Les questions les plus difficiles De la norme GPQA (Questions et réponses de physique de troisième cycle) Le plus large et spécifiquement conçu pour repousser les limites de la capacité des modèles LLM à inférer des sujets avancés de niveau doctorat. Cette norme représente un véritable défi pour la capacité de l’IA à comprendre et à déduire des concepts scientifiques complexes.
- Alors que le GPQA comprend un ensemble de questions de troisième cycle conceptuelles et basées sur des calculs, le GPQA-Diamond isole uniquement les questions les plus difficiles et celles qui nécessitent un raisonnement intensif.
- Ce critère est considéré comme « résistant à Google », ce qui signifie qu’il est difficile d’y répondre même avec un accès Web illimité. Cela en fait un outil précieux pour évaluer la capacité des grands modèles linguistiques à raisonner de manière indépendante.
- Voici un exemple de question GPQA-Diamond :
### GPQA Diamond - Exemple de question (biologie moléculaire) Une cellule eucaryote a développé un mécanisme pour transformer les éléments constitutifs macromoléculaires en énergie. Le processus se déroule dans les mitochondries, qui sont des usines d’énergie cellulaire. Dans la série de réactions redox, l’énergie provenant des aliments est stockée entre les groupes phosphate et utilisée comme monnaie cellulaire universelle. Les molécules chargées d’énergie sont évacuées de la mitochondrie pour servir à tous les processus cellulaires. Vous avez découvert un nouveau médicament antidiabétique et souhaitez déterminer s’il a un effet sur les mitochondries. Vous avez mis en place une série d’expériences avec votre lignée cellulaire HEK293. Laquelle des expériences listées ci-dessous ne vous aidera pas à découvrir le rôle mitochondrial de votre médicament : (A) Extraction par centrifugation différentielle des mitochondries suivie du kit de dosage colorimétrique de l'absorption du glucose (B) Cytométrie de flux après marquage avec 2.5 µM d'iodure de 5,5',6,6'-tétrachloro-1,1',3,3'-tétraéthylbenzimidazolylcarbocyanine (C) Transformation des cellules avec de la luciférase recombinante et lecture au luminomètre après ajout de 5 µM de luciférine au surnageant (D) Microscopie confocale à fluorescence après coloration Mito-RTP des cellules
Dans ce projet, Nous utilisons GPQA-Diamond comme norme de conclusion., comme je l'ai utilisé OpenAI et Recherche profonde Pour évaluer leurs modèles d’inférence. Le choix du GPQA-Diamond comme norme d’évaluation témoigne de sa difficulté et de son importance dans le domaine du développement de l’IA.
(6) Outils utilisés
Dans ce projet, nous utilisons principalement Ollama et évaluations simples De OpenAI. Ollama est une plateforme puissante permettant d'exécuter localement de grands modèles de langage, tandis que simple-evals fournit un cadre permettant d'évaluer les performances de ces modèles.
(i) Ollama
Ollama Il s'agit d'un outil open source qui simplifie l'exécution de grands modèles de langage (LLM) sur notre ordinateur ou sur un serveur local. Olama est une plateforme idéale pour exécuter des modèles d’IA localement.
Il agit comme un gestionnaire et un environnement d'exécution, gérant des tâches telles que les téléchargements et la configuration de l'environnement. Cela permet aux utilisateurs d’interagir avec ces modèles sans avoir besoin d’une connexion Internet constante ou de s’appuyer sur des services cloud. La gestion des modèles de langage locaux de grande taille (LLM) est une fonctionnalité essentielle d'Olama.
Il prend en charge de nombreux grands modèles de langage open source, notamment DeepSeek-R1, et est compatible multiplateforme avec macOS, Windows et Linux. De plus, il offre une configuration simple avec un minimum de tracas et une utilisation efficace des ressources. Ollama vous permet d'exploiter la puissance de l'intelligence artificielle directement sur votre appareil.
ImportantAssurez-vous que votre machine locale dispose de : Accessibilité du GPU Pour Ollama, cela accélère considérablement les performances et rend les analyses comparatives ultérieures plus efficaces par rapport au processeur. Exécutez la commande
nvidia-smiDans le terminal pour vérifier si le GPU est détecté. Cette procédure garantit que les capacités de l'appareil sont maximisées pour exécuter des modèles avec une efficacité élevée.
(ii) Bibliothèque OpenAI simple-evals pour l'évaluation des modèles de langage
Préparer évaluations simples Une bibliothèque légère conçue pour évaluer les modèles de langage à l'aide d'une méthodologie d'évaluation zéro coup avec une invite de chaîne de pensée. Cette bibliothèque comprend des benchmarks d'évaluation populaires tels que MMLU, MATH, GPQA, MGSM et HumanEval, et vise à simuler des scénarios d'utilisation réels pour évaluer les performances des modèles d'IA sur des tâches d'inférence complexes.
Certains d’entre vous connaissent peut-être la bibliothèque d’évaluation la plus populaire et la plus complète d’OpenAI, appelée Évaluations, ce qui est différent de simple-evals.
En fait, la page indique README La spécification simple-evals indique qu'elle n'est pas destinée à remplacer la bibliothèque. Évaluations.
Alors, pourquoi utilisons-nous des évaluations simples ?
La réponse simple est que évaluations simples Il est livré avec des textes d'évaluation intégrés pour les normes d'inférence que nous ciblons (telles que GPQA), ce qui manque à la bibliothèque. Évaluations.
De plus, je n'ai trouvé aucun autre outil ou plateforme, autre que simple-evals, qui offre un moyen direct et natif dans le langage. Python Pour exécuter de nombreuses normes majeures, telles que GPQA, en particulier lorsque vous travaillez avec Ollama.
(7) Résultats de l'évaluation
Dans le cadre de l’évaluation, j’ai sélectionné : 20 questions aléatoires De l'ensemble de questions GPQA-Diamond de 198 questions sur lesquelles travailler Formulaire 14B Distillateur. Il a fallu un total de 216 minutes, soit environ 11 minutes par question.
Le résultat a été quelque peu décevant, car il a enregistré 10 % Seulement, ce qui est nettement inférieur au résultat rapporté de 73.3 % pour le modèle 1B DeepSeek-R671.
Le principal problème que j'ai remarqué est que lors d'un raisonnement interne intensif, Le modèle ne parvenait souvent pas à produire de réponse (par exemple, en renvoyant des codes d’inférence sous forme de lignes finales de sortie) ou fournissait une réponse qui ne correspondait pas au format à choix multiples attendu (par exemple, réponse : A).
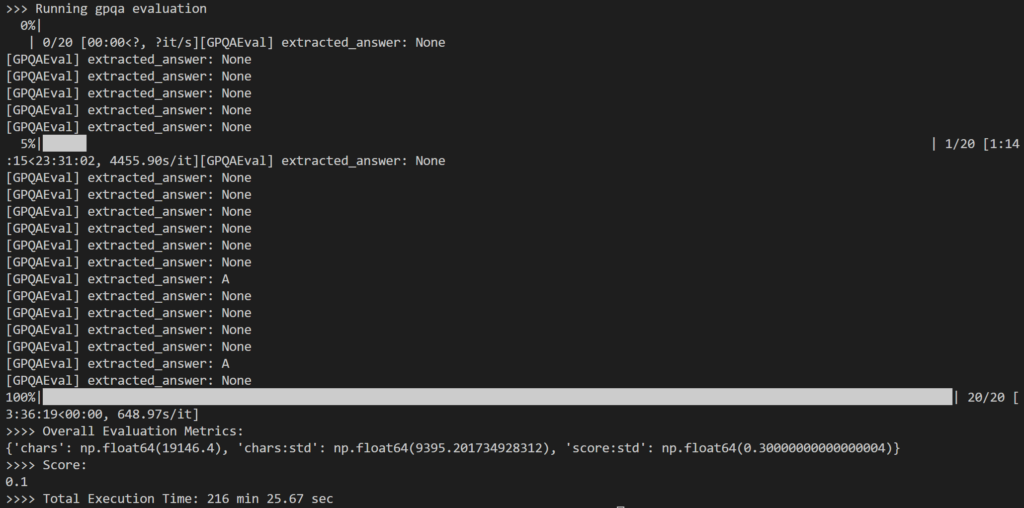
Comme indiqué ci-dessus, de nombreuses sorties ont abouti à : None Parce que la logique regex dans simple-evals n'a pas pu détecter le modèle de réponse attendu dans la réponse LLM.
Bien que la raisonnement de type humain C'était intéressant à observer, car je m'attendais à une meilleure performance en termes de précision dans les réponses aux questions.
J'ai également vu des utilisateurs en ligne mentionner que même le plus grand modèle 32B ne fonctionne pas aussi bien que le o1. Cela a soulevé des doutes quant à l’utilité des modèles d’inférence distillés, en particulier lorsqu’ils ont du mal à fournir des réponses correctes malgré la génération de longues inférences.
Cependant, GPQA-Diamond est un benchmark très exigeant, donc ces modèles peuvent toujours être utiles pour des tâches d'inférence plus simples. Ses exigences de calcul plus faibles le rendent également plus facile.
De plus, l’équipe DeepSeek a recommandé d’exécuter plusieurs tests et de faire la moyenne des résultats dans le cadre du processus d’analyse comparative – quelque chose que j’ai négligé en raison de contraintes de temps.
(8) Guide détaillé étape par étape
Jusqu’à présent, nous avons couvert les concepts de base et les principales conclusions.
Si vous êtes prêt pour une expérience technique pratique, cette section fournit un aperçu approfondi des mécanismes internes et de la mise en œuvre étape par étape. Ce guide technique pratique vous fournira une compréhension complète du fonctionnement du système.
Pour voir (ou copier) Dépôt GitHub compagnon A suivre. Les exigences de configuration de l'environnement virtuel peuvent être trouvées ici. ici.
(i) Configuration initiale – Ollama
Nous commençons par télécharger Ollama. Visite
Page de téléchargement d'Ollama, choisissez votre système d'exploitation et suivez les instructions d'installation correspondantes.
Une fois l'installation terminée, lancez Ollama en double-cliquant sur l'application Ollama (pour Windows et macOS) ou en exécutant la commande ollama serve Dans le terminal.
(ii) Configuration initiale – OpenAI simple-evals
La configuration simple-evals est relativement unique.
Alors que simple-evals se présente comme une bibliothèque, L'absence de dossiers __init__.py Dans le référentiel, cela signifie qu'il n'est pas structuré comme un package Python approprié., ce qui entraîne des erreurs d'importation après le clonage local du référentiel. Cela signifie qu'il ne s'agit pas d'un package Python standard au sens couramment utilisé en ingénierie logicielle.
Puisqu'il n'est pas non plus publié sur PyPI et qu'il manque de fichiers de packaging standard comme setup.py ou pyproject.tomlIl ne peut pas être installé via pip. Cela représente un certain défi pour les nouveaux développeurs.
Heureusement, nous pouvons utiliser Sous-modules Git Comme solution alternative directe. Ces modules vous permettent d'inclure un dépôt Git dans un autre, facilitant ainsi la gestion des dépendances.
"`HTML
Un sous-module Git nous permet d'inclure le contenu d'un autre référentiel Git dans notre projet. Il extrait les fichiers d'un référentiel externe (tel que simple-evals), mais conserve leur historique séparé.
Vous pouvez choisir l'une des deux méthodes (A ou B) pour extraire le contenu de simple-evals :
(a) Si vous clonez mon référentiel de projet
Mon référentiel de projet comprend déjà simple-evals En tant que sous-module, vous pouvez donc simplement exécuter :
git submodule update --init --recursive(b) Si vous l'ajoutez à un projet nouvellement créé.
Pour ajouter manuellement simple-evals en tant que sous-module, exécutez ceci :
git submodule add https://github.com/openai/simple-evals.git simple_evalsNote: que simple_evals À la fin (avec souligner) est très important. Il spécifie le nom du dossier, en utilisant un trait d'union à la place (c'est-à-dire simple-evals) peut entraîner des problèmes d'importation ultérieurs.
Étape finale (pour les deux méthodes)
Après avoir extrait le contenu du référentiel, vous devez créer un fichier. __init__.py Vide dans le dossier simple_evals Le nouveau créé peut être importé en tant qu'unité. Vous pouvez le créer manuellement ou utiliser la commande suivante :
touch simple_evals/__init__.py(iii) Extraction du modèle DeepSeek-R1 via Ollama
L'étape suivante consiste à télécharger le modèle distillé localement de votre choix (par exemple, 14B) à l'aide de cette commande :
Une liste des modèles DeepSeek-R1 disponibles peut être trouvée sur Ollama. ici. Pour de meilleures performances, il est recommandé d'utiliser la dernière version du modèle.
ollama pull deepseek-r1:14b(Quatrièmement) Spécifiez les paramètres
Nous définissons les paramètres dans le fichier YAML de paramètres, comme indiqué ci-dessous :
# config/config.yaml MODEL_NAME : « deepseek-r1:14b » # Nom du modèle (correspond à la liste des modèles Ollama) MODEL_TEMPERATURE : 0.6 # Défini entre 0.5 et 0.7 pour DeepSeek-R1 EVAL_BENCHMARK : « gpqa » GPQA_VARIANT : « diamond » EVAL_N_EXAMPLES : 20
La température du modèle est réglée sur 0.6 (Par rapport à la valeur par défaut typique de 0). Ceci suit les recommandations d'utilisation de DeepSeek, qui suggèrent une plage de température de 0.5 à 0.7 (0.6 est recommandé). Pour éviter les répétitions infinies ou les résultats incohérents. Ce paramètre est nécessaire pour améliorer la qualité de la sortie et assurer sa cohérence.
Ne manquez pas l'occasion de découvrir Recommandations d'utilisation uniques et intéressantes de DeepSeek-R1 – en particulier pour les benchmarks – pour garantir des performances optimales lors de l’utilisation des modèles DeepSeek-R1.
EVAL_N_EXAMPLES Il s’agit du paramètre utilisé pour définir le nombre de questions parmi l’ensemble complet de 198 questions utilisées dans l’évaluation. Ce paramètre est nécessaire pour ajuster le processus d’évaluation en fonction des ressources disponibles et des objectifs spécifiques du test.
(v) Configuration du code Sampler
Pour prendre en charge les modèles de langage basés sur Ollama dans le cadre simple-evals, nous créons une classe wrapper personnalisée nommée OllamaSampler Et garde-le à l'intérieur utils/samplers/ollama_sampler.py. Sampler est un composant essentiel pour tester et évaluer les performances des modèles de langage.
# utils/samplers/ollama_sampler.py import ollama class OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
Dans ce contexte, cela signifie échantillonneur (Samplifier) Une classe Python qui génère une sortie à partir d'un modèle de langage en fonction d'une invite donnée. Cet outil est essentiel pour garantir que des réponses diverses et représentatives sont générées à partir du modèle.
Étant donné que les échantillonneurs dans simple-evals ne couvrent que des fournisseurs comme OpenAI et Claude, nous avons besoin d'une classe d'échantillonneur qui fournit une interface compatible avec Ollama. Cela garantit une intégration transparente avec le cadre d’évaluation.
Vous OllamaSampler Extrait une invite de question GPQA, la soumet au formulaire à une température spécifiée et renvoie une réponse en texte brut. La température est un paramètre important qui contrôle le caractère aléatoire de la sortie.
Méthode incluse _pack_message Pour garantir que le format de sortie correspond à ce qu'attendent les scripts d'évaluation dans simple-evals. Cela garantit la cohérence et la facilité d’analyse.
6. Créer un script d'évaluation
Le code suivant montre comment configurer l’implémentation de l’évaluation dans un fichier. main.py, y compris l'utilisation de la catégorie GPQAEval Depuis la bibliothèque simple-evals pour exécuter des tests de référence GPQA.
Une fonction run_eval() Il s'agit d'un outil d'exécution d'évaluation configurable qui teste les grands modèles de langage (LLM) via Ollama par rapport à des normes telles que GPQA. Cette fonction est nécessaire pour évaluer avec précision les performances des modèles.
# main.py def run_eval(): start_time = time.time() # Charger le fichier de configuration config = load_config("config/config.yaml") # Initialiser l'échantillonneur Ollama (encapsulation du chat Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Sélectionner la classe d'évaluation à utiliser en fonction de EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Exécution de l'évaluation {eval_benchmark}") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Par défaut 1 "num_examples": config["EVAL_N_EXAMPLES"], # Définir sur 20 "variant": config["GPQA_VARIANT"], # Sous-ensemble GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Instanciez et exécutez l'évaluation appropriée evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Exécutez l'évaluation avec l'échantillonneur end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Calculez le temps total pris # Les résultats renvoyés sont un EvalResult qui comprend la liste des SingleEvalResult et des métriques agrégées print(">>>> Métriques d'évaluation globales :", results.metrics) print(">>>> Score :", results.score) print(f">>>> Temps d'exécution total : {int(minutes)} min {secondes:.2f} sec") si __name__ == "__main__": # Exécuter l'évaluation GPQA run_eval()
La fonction charge les paramètres du fichier de configuration, configure la classe d'évaluation appropriée à partir de simple-evals et exécute le modèle via un processus d'évaluation uniforme. Il est enregistré dans un fichier. main.py, qui peut être exécuté à l'aide de la commande python main.py. Cela garantit un processus d’évaluation cohérent et reproductible.
En suivant les étapes ci-dessus, nous avons configuré et exécuté avec succès le benchmark GPQA-Diamond sur le modèle distillé DeepSeek-R1. Ce processus fournit des informations précieuses sur les capacités du modèle.
La ligne du bas
Dans cet article, nous explorons comment nous pouvons combiner des outils comme Ollama et simple-evals d'OpenAI pour explorer et évaluer des modèles issus de DeepSeek-R1, en mettant l'accent sur Évaluation des performances des grands modèles de langage.
Les modèles distillés peuvent ne pas encore correspondre au modèle original de 671 milliards de paramètres sur des benchmarks d'inférence difficiles comme GPQA-Diamond. Cependant, cela illustre comment la distillation peut élargir l’accès aux capacités d’inférence des grands modèles de langage (LLM). Améliorer l'accès aux grands modèles linguistiques C’est un objectif majeur dans ce domaine.
Malgré des performances inférieures sur des tâches complexes de niveau doctorat, ces variantes plus petites peuvent toujours être applicables dans des scénarios moins exigeants, ouvrant la voie à un déploiement local efficace sur une plus large gamme d'appareils. Cela contribue à Déployer localement de grands modèles linguistiques Efficacement.
Les commentaires sont fermés.