

Pourquoi la plupart des modèles de risques de cybersécurité échouent avant même d'avoir commencé
La nécessité d’une réflexion quantitative sur les risques de cybersécurité
Les responsables de la cybersécurité sont confrontés à des questions impossibles. « Quelle est la probabilité d’une faille de sécurité cette année ? » et "Combien cela va-t-il coûter ?" et « Combien devrions-nous dépenser pour l’arrêter ? »
Cependant, la plupart des modèles de risque utilisés aujourd’hui sont encore basés sur des conjectures, de l’instinct et des cartes de risque à code couleur, et non sur des données.
En fait, j'ai trouvé Étude mondiale 2025 de PwC sur la confiance numérique Seulement 15 % des organisations utilisent la modélisation quantitative des risques de manière significative.
Cet article explore pourquoi les modèles traditionnels de risques de cybersécurité sont insuffisants et comment l’application de certains outils statistiques légers comme la modélisation probabiliste offre une meilleure voie à suivre.

Deux grandes écoles de pensée en matière de modélisation des cyber-risques
Les modèles de cyber-risque sont : Cadres ou méthodes systématiques utilisés pour analyser, évaluer et mesurer les menaces de cybersécurité et leur impact potentiel sur les systèmes d’information, les données ou les entreprises.
Les professionnels de la sécurité de l’information utilisent principalement deux méthodes de modélisation des risques différentes au cours du processus d’évaluation des risques : qualitative et quantitative. Il est considéré Modélisation quantitative des cyber-risques Une technique avancée qui nécessite une expertise spécialisée.
Modèles qualitatifs pour l'évaluation des risques
Imaginez deux équipes évaluant le même risque. On attribue au risque une note de 4/5 pour la probabilité et de 5/5 pour l’impact. L'autre équipe lui donne 3/5 et 4/5. Les deux équipes le localisent sur une matrice. Mais aucun des deux ne peut répondre à la question du directeur financier : « Quelle est la probabilité que cela se produise réellement et combien cela nous coûtera-t-il ? »
L’approche qualitative repose sur une évaluation subjective des risques et découle principalement de l’intuition de l’évaluateur. Une approche qualitative aboutit généralement à évaluer la probabilité et l’impact des risques sur une échelle ordinale, par exemple de 1 à 5.
Ensuite, les risques sont localisés dans la matrice des risques pour comprendre où ils s’intègrent sur cette échelle ordinale.
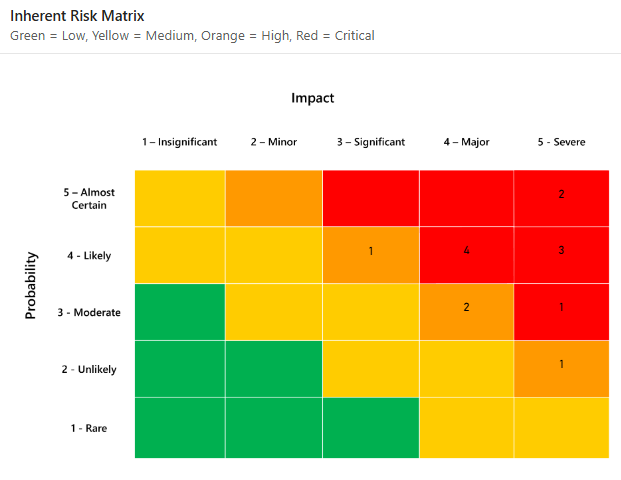
Les deux échelles ordinales sont souvent multipliées ensemble pour aider à hiérarchiser les risques les plus importants en fonction de leur probabilité et de leur impact. À première vue, cela semble raisonnable puisque la définition couramment utilisée du risque en matière de sécurité de l'information est la suivante :
[texte{Risque} = texte{Probabilité} fois texte{Impact}]
Cependant, d’un point de vue statistique, la modélisation qualitative des risques comporte des risques très importants.
Le premier de ces risques est l’utilisation d’échelles ordinales. Bien que l’attribution de nombres à l’échelle ordinale donne l’impression d’un soutien mathématique au modèle, il ne s’agit là que d’une illusion.
Les échelles ordinales sont simplement des étiquettes – il n’y a pas de distance définie entre elles. La distance entre un risque ayant un impact de « 2 » et un impact de « 3 » n’est pas quantifiable. Changer les étiquettes sur l’échelle ordinale en « A », « B », « C », « D » et « E » ne fait aucune différence.
Cela signifie à son tour que notre formulation du risque est erronée lorsque nous utilisons une modélisation qualitative. Il est impossible de calculer la probabilité de « B » multipliée par l’effet de « C ».
Un autre piège majeur est la modélisation de l’incertitude. Lorsque nous modélisons les cyber-risques, nous modélisons des événements futurs incertains. En fait, il existe toute une gamme de résultats qui peuvent se produire.
La distillation du risque cybernétique en estimations ponctuelles (telles que « 20/25 » ou « Élevé ») ne rend pas compte de la distinction importante entre « la perte annuelle la plus probable est de 1 million de dollars » et « il y a 5 % de chances d’une perte de 10 millions de dollars ou plus ».
Modélisation quantitative des risques : analyse avancée
Imaginez une équipe effectuant une évaluation des risques. Ils estiment que les résultats pourraient varier de 100 10 à 10 millions de dollars. En exécutant une simulation de Monte Carlo, ils extraient une probabilité de 480 % de dépasser XNUMX million de dollars de pertes annuelles et une perte attendue de XNUMX XNUMX dollars. Maintenant, lorsque le directeur financier demande : « Quelle est la probabilité que cela se produise et quel sera le coût ? »L’équipe peut réagir avec des données, pas seulement avec de l’intuition.
Cette approche déplace la conversation des classifications de risques vagues vers Possibilités et impact financier potentiel, une langue que les dirigeants comprennent.
Si vous avez une formation en statistiques, un concept en particulier devrait ressortir ici :
Probabilité.
La modélisation des risques de cybersécurité est, à la base, une tentative de quantifier la probabilité que certains événements se produisent et l’impact s’ils se produisent. Cela ouvre la porte à une variété d’outils statistiques, tels que la simulation de Monte Carlo, qui peuvent modéliser l’incertitude beaucoup plus efficacement que les mesures ordinales.
La modélisation quantitative des risques utilise des modèles statistiques pour attribuer des valeurs en dollars aux pertes et modéliser la probabilité que ces événements de perte se produisent, capturant ainsi l'incertitude future.
Bien que l’analyse qualitative puisse parfois se rapprocher du résultat le plus probable, elle ne parvient pas à saisir toute la gamme des incertitudes, comme les événements rares mais impactants, connus sous le nom de « risque à longue traîne ».
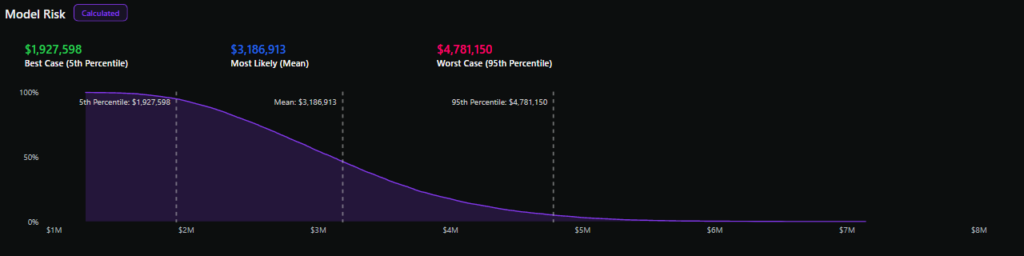
La courbe d'excédent de perte trace la probabilité de dépasser un montant de perte annuel donné sur l'axe des y et différents montants de perte sur l'axe des x, ce qui donne une ligne descendante.
L’extraction de différents pourcentages de la courbe d’excédent de pertes, tels que le 90e percentile, la médiane et le XNUMXe percentile, peut donner une idée des pertes annuelles potentielles pour un risque avec une confiance de XNUMX %.
Alors qu'une estimation ponctuelle de l'analyse qualitative peut approximer les risques les plus probables (en fonction de la précision du jugement des évaluateurs), l'analyse quantitative capture l'incertitude des résultats, même ceux qui sont rares mais toujours possibles (connus sous le nom de « risque à longue traîne »).
Au-delà du cyber-risque : améliorer les modèles de risque en cybersécurité
Pour améliorer nos modèles de risque en matière de sécurité de l’information, il suffit de regarder à l’extérieur, notamment vers les technologies utilisées dans d’autres domaines. Les modèles de risque ont considérablement évolué dans diverses applications, telles que la finance, l’assurance, la sécurité aérienne et la gestion de la chaîne d’approvisionnement. Ces domaines fournissent des informations précieuses qui peuvent être appliquées à la cybersécurité.
Les équipes financières utilisent des modèles pour gérer le risque du portefeuille d’investissement en utilisant des statistiques bayésiennes similaires. Alors que les équipes d’assurance modélisent les risques à l’aide de modèles actuariels sophistiqués. L’industrie aéronautique modélise le risque de défaillance des systèmes à l’aide de modèles de probabilité. Les équipes de gestion de la chaîne d’approvisionnement modélisent les risques à l’aide de simulations probabilistes. Ces méthodologies fournissent une base solide pour développer des modèles de cyber-risque efficaces.
Les outils existent déjà. Les fondements mathématiques sont bien compris. D’autres industries ont ouvert la voie. Il est désormais temps pour la cybersécurité d’adopter des modèles de risque quantitatifs pour prendre des décisions meilleures et plus éclairées, conduisant à de meilleures stratégies de cybersécurité et à une réduction des pertes potentielles. L’adoption de ces modèles quantitatifs représente une étape cruciale vers une gestion plus efficace des cyber-risques.
الخلاصة الرئيسية
| Analyse qualitative | Analyse quantitative |
| Échelles ordinales (1-5) | Modélisation probabiliste |
| intuition personnelle | précision statistique |
| Points d'évaluation uniques | Répartition des risques |
| Cartes thermiques et codes couleur | Courbes de dépassement des pertes |
| Ignore les événements rares mais graves | Capture le risque à longue traîne |
Les commentaires sont fermés.