

Explication : Comment la régularisation L1 sélectionne-t-elle automatiquement les fonctionnalités ?
Comprendre le processus de sélection automatique des fonctionnalités effectué par la régularisation L1 (LASSO).
La sélection de fonctionnalités est le processus de sélection d’un sous-ensemble optimal de fonctionnalités à partir d’un ensemble donné de fonctionnalités ; Le sous-ensemble optimal est celui qui maximise les performances du modèle sur la tâche donnée.
L'identification des fonctionnalités peut être un processus manuel ou plutôt explicite lorsqu'elle est effectuée à l'aide de méthodes de filtrage ou méthodes wrapper. Dans ces méthodes, les fonctionnalités sont ajoutées ou supprimées de manière itérative en fonction de la valeur d’une métrique fixe, qui détermine l’importance de la fonctionnalité dans l’établissement d’une prédiction. Les mesures peuvent être un gain d'information, une variance ou une statistique du chi carré, et l'algorithme prendra la décision d'accepter/rejeter la fonctionnalité en tenant compte d'un seuil fixe sur la mesure. Il convient de noter que ces méthodes ne font pas partie de la phase d’apprentissage du modèle et sont exécutées avant celle-ci.
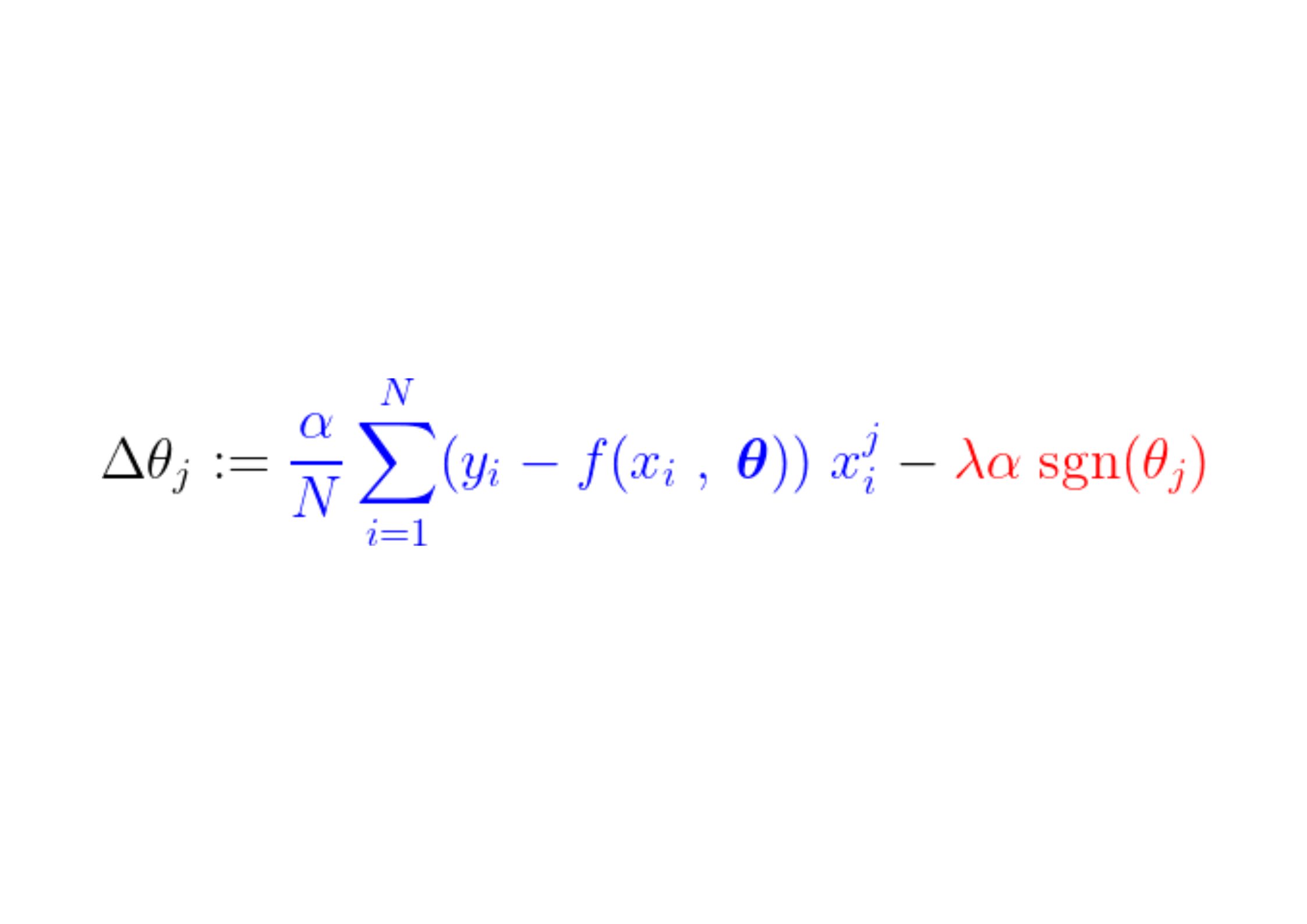
Vous Méthodes intégrées En sélectionnant implicitement des fonctionnalités, sans utiliser de critères de sélection prédéfinis, et en les extrayant des données d'entraînement elles-mêmes. Ce processus d’identification des caractéristiques essentielles fait partie de la phase de formation du modèle. Le modèle apprend à identifier les caractéristiques et à faire des prédictions pertinentes en même temps. Dans les sections suivantes, nous décrirons le rôle de la régularisation dans ce processus essentiel de sélection de fonctionnalités, en nous concentrant sur la régularisation L1 et son rôle dans l’amélioration des modèles d’apprentissage automatique.
Normalisation et complexité des modèles : stratégies avancées pour améliorer les performances
La régularisation est le processus de pénalisation de la complexité du modèle pour éviter le surajustement et parvenir à une généralisation à la tâche.
Ici, la complexité du modèle est analogue à sa capacité à s’adapter aux modèles des données d’apprentissage. En supposant un modèle polynomial simple dans 'x« dans une certaine mesure »d« Plus le score est élevé »dPour les polynômes, le modèle dispose d’une plus grande flexibilité pour capturer des modèles dans les données observées. Cette flexibilité accrue peut conduire le modèle à mémoriser les données d’entraînement plutôt qu’à apprendre les véritables modèles, ce qui réduit sa capacité à généraliser à de nouvelles données.
Sur-apprentissage et sous-apprentissage
Lorsqu'on essaie d'ajuster un modèle polynomial avec un degré d = 2 Sur un ensemble d’échantillons d’apprentissage tirés d’un polynôme du troisième ordre avec un peu de bruit, le modèle ne sera pas en mesure de capturer de manière adéquate la distribution d’échantillonnage. Le modèle manque tout simplement La flexibilité ou complexité Requis pour la modélisation des données générées par des polynômes de degré 3 (ou supérieur). On dit que ce modèle est sous-équipé Sur les données de formation. Une sous-charge indique que le modèle est trop simple et ne peut pas capturer les modèles sous-jacents dans les données.
En travaillant avec le même exemple, nous supposons maintenant que nous avons un modèle avec un degré de d = 6. Maintenant, avec une complexité accrue, il devrait être facile pour le modèle d’estimer le polynôme cubique d’origine qui a été utilisé pour générer les données (par exemple, définir les coefficients de tous les termes avec un exposant > 3 à 0). Si le processus de formation n’est pas terminé à temps, le modèle continuera à utiliser sa flexibilité supplémentaire pour réduire davantage l’erreur et commencera également à capturer des échantillons bruyants. Cela réduira considérablement l'erreur d'entraînement, mais le modèle est désormais suréquipements Sur les données de formation. Le bruit changera dans les conditions réelles (ou dans la phase de test) et toute connaissance basée sur la prédiction sera perturbée, ce qui entraînera une erreur de test élevée. La surcharge signifie que le modèle est trop complexe et apprend le bruit plutôt que le signal réel.
Comment déterminer la complexité optimale du modèle ?
Dans la pratique, nous avons souvent une compréhension limitée, voire inexistante, du processus de génération de données ou de la véritable distribution des données. Trouver le modèle optimal avec la complexité appropriée, de sorte qu'il n'y ait pas de sous-ajustement ou de surajustement, est un défi important. Cela nécessite l’utilisation de méthodes efficaces pour évaluer les performances des modèles et déterminer la complexité appropriée qui permet d’obtenir le meilleur équilibre entre précision et généralité. En utilisant des mesures et des techniques d’évaluation appropriées telles que la validation croisée, les professionnels peuvent identifier le modèle qui fonctionne le mieux sur des données invisibles, évitant ainsi les problèmes de sur- ou de sous-ajustement.
Une technique possible consiste à commencer avec un modèle suffisamment robuste, puis à réduire sa complexité par sélection de fonctionnalités. Moins il y a de fonctionnalités, moins le modèle est complexe.
Comme nous l’avons vu dans la section précédente, la sélection de fonctionnalités peut être explicite (méthodes de filtrage, méthodes de convolution) ou implicite. Les fonctionnalités redondantes qui ne sont pas très importantes pour déterminer la valeur de la variable cible doivent être supprimées pour éviter que le modèle n'apprenne des modèles non corrélés. La régularisation accomplit également une tâche similaire. Alors, comment la régularisation et la sélection de fonctionnalités sont-elles liées à la réalisation d’un objectif commun de complexité optimale du modèle ? La réduction de la complexité des modèles d’apprentissage automatique est essentielle pour améliorer les performances et éviter le surapprentissage, sur lequel se concentrent la régularisation et la sélection de fonctionnalités.
La régularisation L1 comme déterminant de caractéristique
Poursuivant notre modèle polynomial, nous le représentons comme une fonction f, avec des entrées x, et les transactions θ et diplôme d،
![]()
Pour un modèle polynomial, chaque puissance de l'entrée peut être considérée x_i Comme avantage, pour former un vecteur de la forme suivante :
![]()
Nous définissons également une fonction objective, dont la minimisation conduit aux paramètres optimaux. * Le terme comprend : régularisation (Règlement) qui pénalise la complexité des modèles.
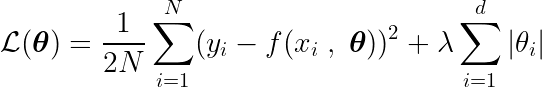
Pour trouver le minimum de cette fonction, nous devons analyser tous les points critiques, c'est-à-dire les points où la dérivée est nulle ou indéfinie.
La dérivée partielle peut être écrite par rapport à l'un des paramètres, θj, Comme suit:
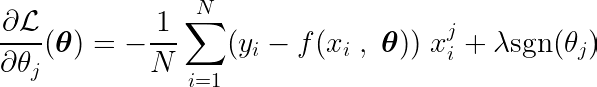
où la fonction est définie signe Comme suit:
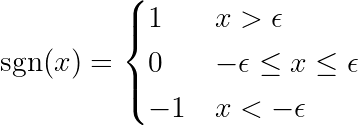
NoteLa dérivée d'une fonction absolue est différente de la fonction signe (sgn) définie ci-dessus. La dérivée d'origine n'est pas définie à x = 0. Nous étendons la définition pour supprimer le point d'inflexion à x = 0 et pour rendre la fonction différentiable sur toute sa plage. De plus, les cadres d’apprentissage automatique (ML) utilisent ces fonctions étendues lorsque les calculs sous-jacents impliquent la fonction absolue. Regarde ça ! lien Dans le forum PyTorch.
En calculant la dérivée partielle de la fonction objective par rapport à un seul coefficient θj, et en l'égalant à zéro, nous pouvons construire une équation qui relie la valeur optimale de θj Avec des prédictions, des objectifs et des fonctionnalités.
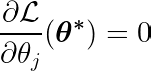
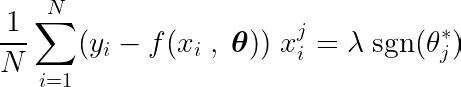
Examinons l’équation ci-dessus. En supposant que les entrées et les cibles étaient centrées autour de la moyenne (c'est-à-dire que les données ont été standardisées lors de l'étape de prétraitement), le terme du côté gauche (LHS) représente effectivement variance Entre le numéro de caractéristique j et la différence entre les valeurs attendues et cibles.
La covariance statistique entre deux variables détermine le degré d’influence d’une variable sur la valeur de la deuxième variable (et vice versa).
La fonction de signe du côté droit force la variation du côté gauche à prendre seulement trois valeurs (puisque la fonction de signe ne renvoie que -1, 0 et 1). Si la fonctionnalité j Inutile et n'affecte pas les prédictions, la variance sera proche de zéro, rendant le coefficient correspondant θj* Zéro. Cela entraîne la suppression de la fonctionnalité du modèle. Ce processus permet de réduire la complexité et d’améliorer les performances du modèle.
Imaginez la fonction du signe comme un sillon creusé par l’eau. Vous pouvez marcher dans le ravin (c'est-à-dire dans le lit de la rivière), mais pour en sortir, vous rencontrerez d'énormes barrières ou des rapides abrupts. La régularisation L1 crée un effet de « seuil » similaire au gradient de la fonction de perte. Le gradient doit être suffisamment fort pour briser les barrières ou devenir nul, ce qui rendrait finalement la valeur du coefficient nulle.
Pour fournir un exemple plus réaliste, considérons un ensemble de données contenant des échantillons dérivés d’une ligne droite (paramétrée à deux facteurs) avec un peu de bruit ajouté. Le modèle optimal ne doit pas avoir plus de deux paramètres, sinon il s'adaptera au bruit dans les données (avec la liberté/puissance supplémentaire du polynôme). La modification des coefficients de puissance supérieurs dans un modèle polynomial n’affecte pas la différence entre les cibles et les prédictions du modèle, et réduit ainsi leur variance avec la fonctionnalité.
Au cours du processus de formation, une étape fixe est ajoutée/soustraite du gradient de la fonction de perte. Si le gradient de la fonction de perte (MSE – erreur quadratique moyenne) est inférieur au pas constant, le coefficient atteindra finalement une valeur de 0. Notez l'équation ci-dessous, qui décrit comment les coefficients sont mis à jour à l'aide de la descente de gradient :

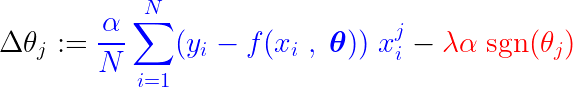
Si la partie bleue ci-dessus est plus petite que La, ce qui est un très petit nombre en soi, alors Δθj C'est presque un pas régulier. La. Le signal pour cette étape (partie rouge) dépend de : sgn(θj), dont la sortie dépend de θj. Si la valeur est θj Positif, c'est-à-dire supérieur à ε, Le sgn(θj) est égal à 1, ce qui fait Δθj Approximativement égal à -La, le poussant vers zéro.
Pour supprimer le pas constant (partie rouge) qui rend le coefficient nul, le gradient de la fonction de perte (partie bleue) doit être supérieur à la taille du pas. Pour obtenir un gradient plus important pour la fonction de perte, la valeur de la fonctionnalité doit affecter de manière significative la sortie du modèle.
C'est ainsi que la fonctionnalité, ou plus précisément son paramètre correspondant, dont la valeur n'est pas liée à la sortie du modèle, est mise à zéro par la régularisation L1 pendant l'entraînement.
Lectures complémentaires et conclusion
- Pour obtenir plus d'informations sur ce sujet, j'ai posté une question sur Reddit r/MachineLearning, etSuivi Il contient différentes interprétations que vous voudrez peut-être lire.
- Madiyar Aitbayev a également blog intéressant Couvre la même question, mais avec une explication technique.
- مدونة Brian King explique l’organisation d’un point de vue probabiliste.
- هذا النقاش Sur le site CrossValidated, il explique pourquoi le critère L1 encourage les modèles clairsemés. مدونة Un article détaillé de Mukul Ranjan explique pourquoi la norme L1 encourage les transactions à devenir nulles et la norme L2 ne le fait pas.
« La régularisation L1 sélectionne des fonctionnalités » est une affirmation simple avec laquelle la plupart des apprenants ML sont d’accord, sans entrer dans les détails de son fonctionnement interne. Ce blog est une tentative de présenter ma compréhension et mon modèle mental aux lecteurs afin de répondre à la question de manière intuitive. Pour des suggestions et des doutes, vous pouvez trouver mon email à Mon site web. Continuez à apprendre et passez une merveilleuse journée !
Les commentaires sont fermés.