

Amélioration de la détection dans les modèles Transformer en ajoutant du bruit d'entraînement
Les modèles de vision Transformer modernes ajoutent du bruit pour améliorer les performances de détection d'objets 2D et 3D. Dans cet article, nous allons apprendre comment fonctionne ce mécanisme et discuter de sa contribution à l'amélioration de la précision des modèles de détection d'objets, en nous concentrant sur l'utilisation de techniques telles que la débruitage dans le processus de formation.

Modèles de transformateurs pour la vision précoce
DETR – DEtection TRansformer (Carion, Massa et al. 2020), l'une des premières architectures Transformer pour la détection d'objets, utilisait des requêtes encodeur-décodeur apprises pour extraire des informations de détection à partir de jetons d'image. Ces requêtes ont été initialisées de manière aléatoire et l’architecture n’a imposé aucune contrainte obligeant ces requêtes à apprendre des objets de type ancre. Bien qu'il ait obtenu des résultats similaires avec Faster-RCNN, son inconvénient était une convergence lente : 500 époques étaient nécessaires pour l'entraîner (DN-DETR, Li et al., 2024). Les architectures plus récentes basées sur DETR utilisaient un pooling déformable qui permettait aux requêtes de se concentrer uniquement sur des régions spécifiques de l'image (Zhu et al., Deformable DETR : Deformable Transformers For End-To-End Object Detection, 2020), tandis que d'autres (Liu et al., DAB-DETR : Dynamic Anchor Boxes Are Better Queries For DETR, 2022) utilisaient des ancres spatiales (générées à l'aide de k-means, d'une manière similaire à celle des CNN basés sur des ancres), qui étaient codées dans les requêtes initiales. Les connexions de saut forcent le bloc décodeur Transformer à apprendre les carrés comme valeurs de pente à partir des ancres. Les couches d'attention déformables utilisaient des ancres pré-codées pour échantillonner les caractéristiques spatiales de l'image et les utiliser pour générer des jetons d'attention. Au cours de la formation, le modèle apprend les ancrages idéaux à utiliser. Cette approche apprend au modèle à utiliser explicitement des fonctionnalités telles que la taille de la boîte dans ses requêtes.
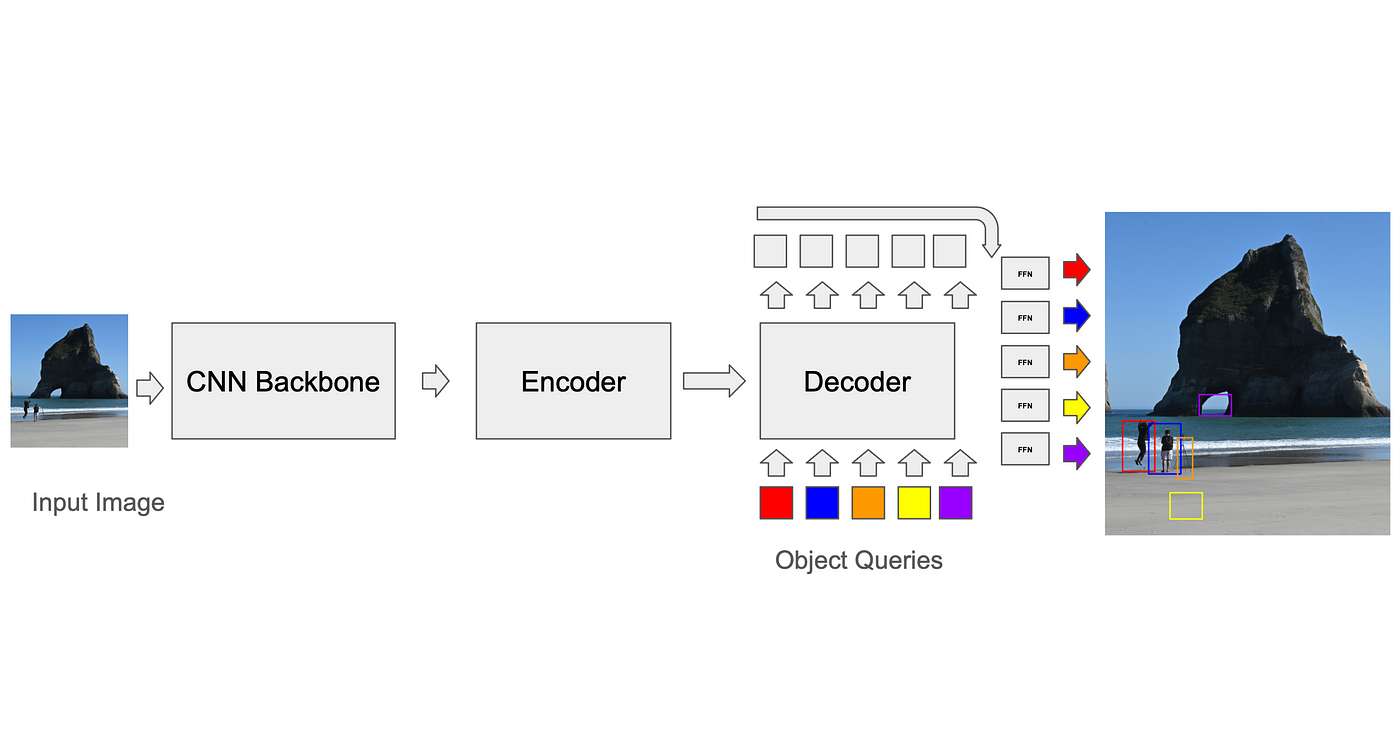
Correspondance des prédictions avec les faits réels : algorithme de correspondance binaire
Pour calculer la perte, le formateur doit d'abord faire correspondre les prédictions du modèle aux cases de vérité terrain (GT). Bien que les CNN basés sur l'ancre aient des solutions relativement simples à ce problème (par exemple, chaque ancre ne peut être associée qu'aux boîtes GT de son voxel pendant la formation, et dans l'inférence, la suppression non maximale est utilisée pour supprimer les détections qui se chevauchent), la norme pour les transformateurs, développée par DETR, consiste à utiliser un algorithme de correspondance binaire appelé algorithme hongrois. À chaque itération, l'algorithme trouve la meilleure correspondance entre la prédiction et la vérité terrain (une correspondance qui optimise une fonction de coût, telle que la distance quadratique moyenne entre les coins des boîtes, additionnée sur toutes les boîtes). La perte entre les paires prédicteur-vérité terrain est ensuite calculée et peut être rétropropagée. Les sur-prédictions (prédictions sans correspondance GT) entraînent une perte discrète qui les encourage à réduire leur niveau de confiance. Ce processus est nécessaire pour améliorer la précision du modèle et réduire les erreurs.
Le problème
La complexité temporelle de l'algorithme hongrois est o(n³). Il est intéressant de noter qu'il ne s'agit pas nécessairement d'un goulot d'étranglement dans la qualité de la formation : The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective, Fenoaltea et al., 2021, montre que l'algorithme est instable, ce qui signifie qu'un petit changement dans sa fonction objective peut conduire à un grand changement dans son résultat de correspondance, ce qui conduit à des objectifs de formation de requêtes incohérents. Les implications pratiques de la formation des transformateurs sont que les requêtes d’objets peuvent passer d’un objet à l’autre et qu’il faut beaucoup de temps pour apprendre les meilleures fonctionnalités pour la convergence. En d’autres termes, l’instabilité de l’algorithme conduit à des oscillations dans le processus de formation, ce qui nécessite plus de temps pour atteindre les meilleurs résultats.
DN-DETR (Détection d'objets par élimination du bruit)
Li et al. a proposé une solution élégante au problème de correspondance instable, qui a ensuite été adoptée dans de nombreux autres travaux, notamment DINO, Mask DINO, Group DETR et d'autres.
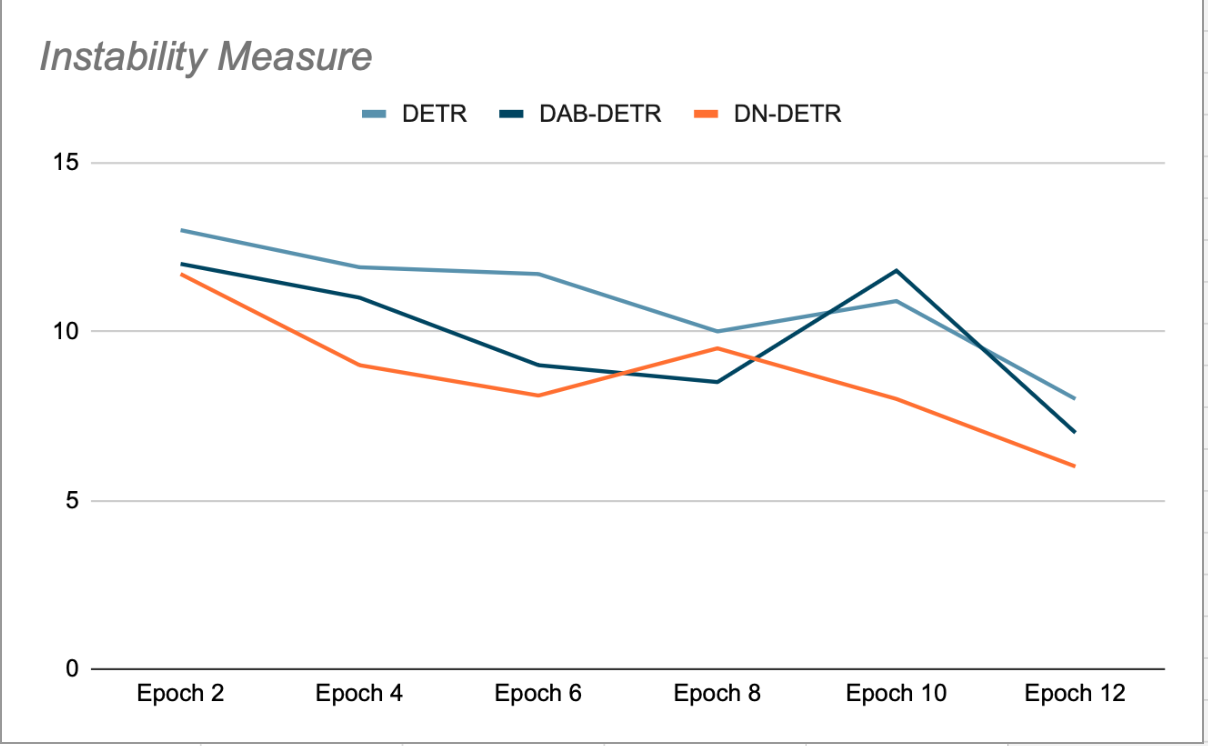
L'idée principale de DN-DETR est d'améliorer la formation en créant Points de pivot imaginaires faciles à inclinerIl ignore le processus de correspondance. Cela se fait pendant l'apprentissage en ajoutant une petite quantité de bruit aux tuiles GT (true ground) et en alimentant ces tuiles bruyantes comme ancres pour les requêtes du décodeur. Les requêtes DN sont masquées des requêtes organiques et vice versa, afin d'éviter toute attention croisée susceptible d'interférer avec l'apprentissage. Les détections générées par ces requêtes sont déjà appariées à leurs tuiles GT sources et ne nécessitent pas de correspondance bipartite. Les auteurs de DN-DETR ont montré que lors des phases de validation à la fin de chaque époque (où la suppression du bruit est désactivée), cela améliore la stabilité du modèle par rapport à DETR et DAB-DETR, ce qui signifie que les requêtes Plus sont cohérentes dans leur correspondance avec l'objet GT au cours des époques successives (voir Figure 2).
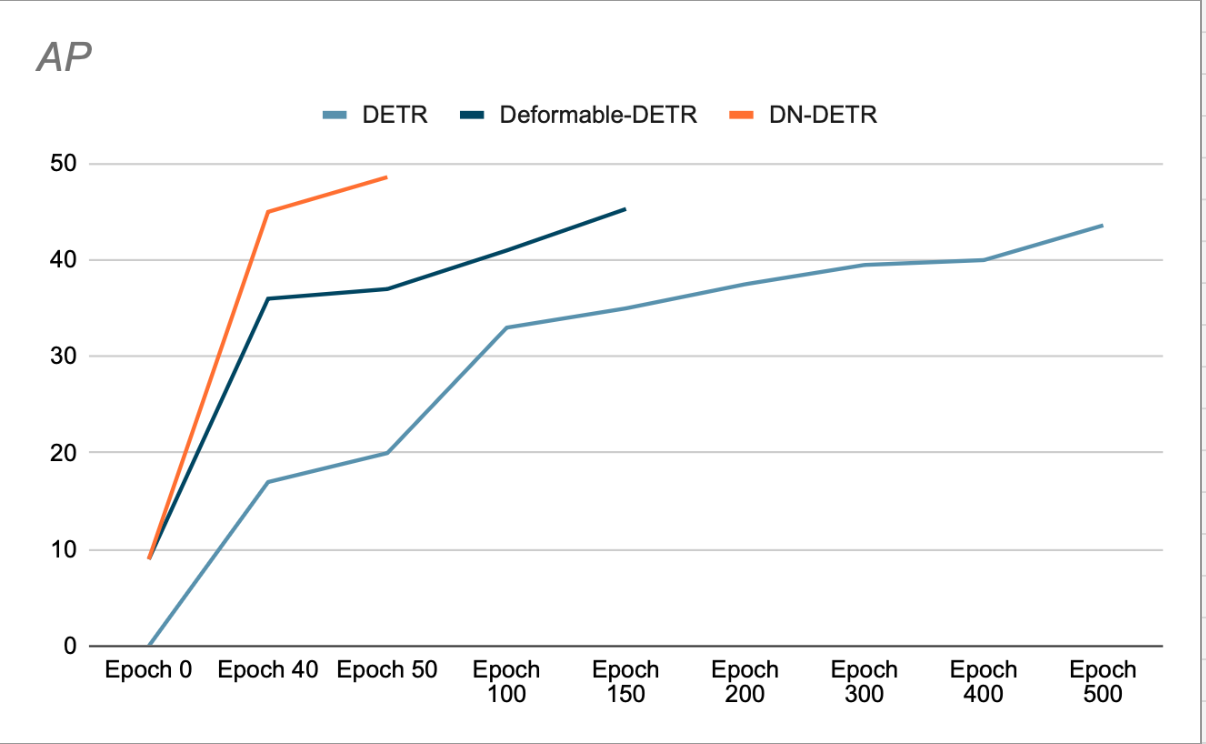
Les auteurs montrent que l’utilisation de DN accélère la convergence et permet d’obtenir de meilleurs résultats de détection. (Voir Figure 3). Leur étude de suppression montre une augmentation de 1.9 % de l'AP (précision moyenne) sur l'ensemble de données de détection COCO, par rapport au SOTA précédent (DAB-DETR, AP 42.2 %), lors de l'utilisation de ResNet-50 comme dorsale.
DINO et suppression du bruit de contraste
DINO a développé cette idée plus loin, en ajoutant l'apprentissage contrastif au mécanisme de suppression du bruit : en plus de l'exemple positif, DINO crée une autre version bruitée de chaque GT, qui est mathématiquement construite pour être plus éloignée du GT que l'exemple positif (voir Figure 4). Cette version est utilisée comme exemple négatif pour la formation : le modèle apprend à accepter la détection la plus proche de la vérité fondamentale et à rejeter la détection la plus éloignée (en apprenant à prédire la classe « aucun objet »).
De plus, DINO permet le clustering multiple pour la réduction du bruit contrastif (CDN) – plusieurs ancres bruyantes pour chaque objet GT – tirant le meilleur parti de chaque itération d'entraînement.
Les auteurs du DINO ont signalé une précision moyenne (AP) de 49 % (sur COCO val2017) lors de l'utilisation d'un CDN.
Les modèles temporels modernes qui doivent suivre des objets d'une image à l'autre, tels que Sparse4Dv3, utilisent des CDN et ajoutent des groupes de débruitage temporel, où certaines ancres DN réussies sont stockées (avec les ancres non DN apprises) pour être utilisées dans les images suivantes, ce qui améliore les performances du modèle dans le suivi des objets.

مناقشة
Le débruitage (DN) semble améliorer la vitesse de convergence et les performances ultimes des détecteurs de transformateurs de vision. Cependant, lorsque l’on examine le développement des différentes méthodes mentionnées ci-dessus, les questions suivantes se posent :
- DN améliore les modèles qui utilisent des ancres apprenables. Mais les ancres apprenables sont-elles vraiment importantes ? DN améliorera-t-il également les modèles qui utilisent des ancres non apprenables ?
- La principale contribution de DN à la formation est d’ajouter de la stabilité au processus de descente de gradient en contournant la correspondance bipartite. Mais la correspondance binaire semble exister principalement parce que la norme dans le travail de transformation est d'éviter les contraintes spatiales sur les requêtes. Ainsi, si nous limitons manuellement les requêtes à des emplacements d’image spécifiques et abandonnons la correspondance binaire (ou utilisons une version simplifiée de la correspondance binaire, qui est exécutée sur chaque patch d’image séparément), le DN améliorera-t-il toujours les résultats ?
Je n’ai pas réussi à trouver d’ouvrages apportant des réponses claires à ces questions. Mon hypothèse est qu'un modèle utilisant des ancres non apprenables (à condition que les ancres ne soient pas trop rares) et des requêtes spatialement contraintes, 1 – ne nécessitera pas d'algorithme de correspondance binaire, et 2 – ne bénéficiera pas de DN dans la formation, puisque les ancres sont déjà connues et il n'y a aucun gain dans l'apprentissage de la régression à partir d'autres ancres éphémères.
Si les ancres sont fixes mais dispersées, je peux voir comment l'utilisation d'ancres éphémères facilite la descente et peut fournir un bon départ au processus de formation.
Anchor-DETR (Wand et al., 2021) compare la distribution spatiale des ancres apprenables et non apprenables, ainsi que les performances des modèles respectifs, et à mon avis, l'apprenabilité n'ajoute pas beaucoup de valeur aux performances du modèle. Il convient de noter qu'ils utilisent l'algorithme hongrois dans les deux méthodes, il n'est donc pas clair s'ils pourraient abandonner la correspondance binaire tout en maintenant les performances.
Une considération à garder à l’esprit est qu’il peut y avoir des raisons productives d’éviter le NMS dans l’inférence, ce qui encourage l’utilisation de l’algorithme hongrois dans la formation.
Où la suppression du bruit peut-elle vraiment être importante ? À mon avis - dans Suivi. Lors du suivi, le modèle est doté d'un flux vidéo et doit non seulement détecter plusieurs objets sur des images consécutives, mais également conserver l'identité unique de chaque objet détecté. Les modèles de transformateur temporel, c'est-à-dire les modèles qui utilisent la nature séquentielle du streaming vidéo, ne traitent pas les images individuelles de manière indépendante. Au lieu de cela, il maintient une banque qui stocke les découvertes précédentes. Lors de la formation, le modèle de suivi est encouragé à régresser à partir de la détection d'objet précédente (ou plus précisément, du fixateur associé à la détection d'objet précédente), plutôt que de simplement régresser à partir du fixateur le plus proche. Étant donné que la découverte précédente ne se limite pas à un réseau fixe de stabilisateurs, il est plausible que la flexibilité stimulée par DN soit bénéfique. J’aimerais beaucoup lire de futurs ouvrages qui abordent ces questions.
Voilà tout sur la suppression du bruit et sa contribution aux transformateurs de vision ! Si vous avez aimé mon article, vous êtes invité à visiter certains de mes autres articles sur l'apprentissage profond et l'apprentissage automatique et vision par ordinateur!
Les commentaires sont fermés.