

J'ai essayé la nouvelle fonctionnalité de génération d'images natives de Gemini, et c'est absolument incroyable.
Résumé:
- Google a lancé la génération et l'édition d'images natives à l'aide de la nouvelle version bêta de Gemini 2.0 Flash.
- La fonctionnalité est désormais disponible gratuitement sur AI Studio et vous pouvez générer et modifier une série d'images coordonnées à l'aide de commandes de texte simples.
- Vous pouvez supprimer et ajouter des éléments, insérer du texte, colorier des images, créer une histoire visuelle et bien plus encore.
Nous entendons le terme « nativement multimodal » dans l’IA depuis plus d’un an, mais les entreprises ont jusqu’à présent mis du temps à exploiter tout le potentiel multimodal de leurs modèles d’IA. Google a enfin publié son dernier prototype, le « Gemini 2.0 Flash Experimental », avec… Capacité à générer et à éditer des images originalesOh.
Maintenant, vous vous demandez peut-être quelle est l’importance de la génération d’images ? La génération d'images IA est disponible avec tous les principaux chatbots IA comme ChatGPT depuis un certain temps. Eh bien, lorsque nous générons des images IA sur ChatGPT ou Gemini, elles sont dirigées vers un modèle spécialisé basé sur la diffusion comme Dall-E 3 ou Imagen 3. Ces modèles sont formés sur des images et sont conçus uniquement pour générer des images ; Il s’agit d’une extension du modèle d’IA principal, et non d’une partie de celui-ci.
Cependant, les modèles de vision linguistique tels que GEMINI Nativement multimédia, ce qui signifie qu'il peut comprendre, générer et modifier à la fois du texte et des images de manière inhérente. Jusqu’à présent, aucune entreprise technologique n’a mis cette capacité à la disposition des utilisateurs. OpenAI a démontré sa fonctionnalité de génération d'images natives avec GPT-4o en 2024, mais encore une fois, elle n'a jamais été publiée.
 Avec la fonction de génération d'images originale, vous obtiendrez : Une meilleure coordination Là où les modèles multimodaux sont formés sur un vaste ensemble de données de différents supports. En conséquence, ces modèles ont une meilleure compréhension des concepts et démontrent une connaissance plus large du monde.
Avec la fonction de génération d'images originale, vous obtiendrez : Une meilleure coordination Là où les modèles multimodaux sont formés sur un vaste ensemble de données de différents supports. En conséquence, ces modèles ont une meilleure compréhension des concepts et démontrent une connaissance plus large du monde.
Outre la génération d'images, vous pouvez les modifier facilement grâce à de simples commandes textuelles. Par exemple, vous pouvez importer une image et demander au modèle d'ajouter des lunettes de soleil, d'insérer du texte en gras, de supprimer des objets, etc. Contrairement aux modèles de diffusion qui régénèrent l'image entière à chaque nouvelle commande, les modèles multimédias natifs préservent la cohérence entre les différentes modifications.
Créer des images à l'aide de la démo Flash de Gemini 2.0
Actuellement, la fonctionnalité de création d’image d’origine n’est pas disponible pour les utilisateurs publics. La démo Flash de Gemini 2.0 avec génération d'images natives est uniquement disponible sur la plateforme AI Studio de Google (Visite) gratuitement.
Après avoir prévisualisé le modèle sur AI Studio, il sera publié sur Gemini pour que tout le monde puisse l'utiliser dans un avenir proche. Cependant, j'ai essayé le nouveau modèle Gemini avec la fonction de création d'images, et ce fut une expérience très excitante.
Tout d’abord, j’ai commencé avec un guide visuel pour montrer la cohérence de la capacité de génération d’images de Gemini. J'ai demandé à Gemini de créer un guide visuel sur la façon de faire une omelette, en créant une photo pour chaque étape du processus.
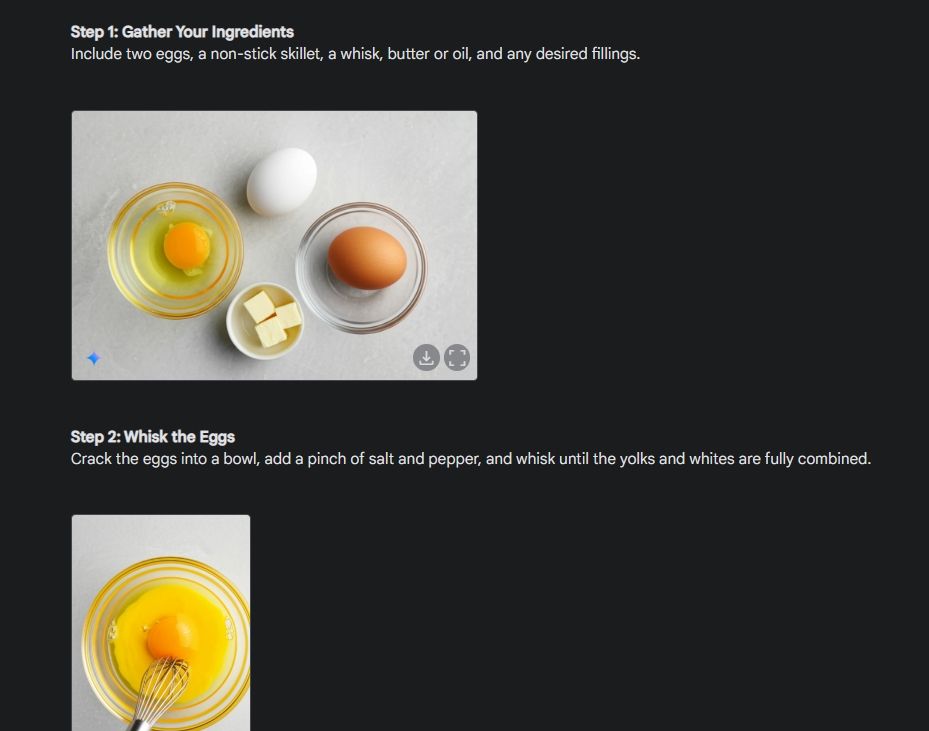
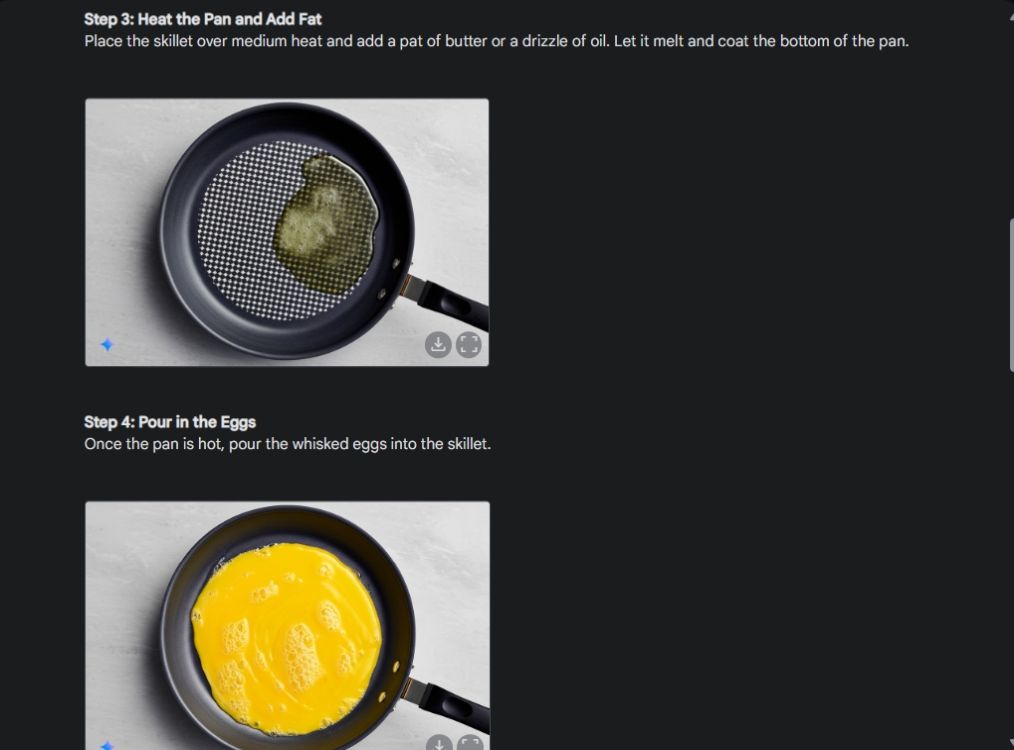

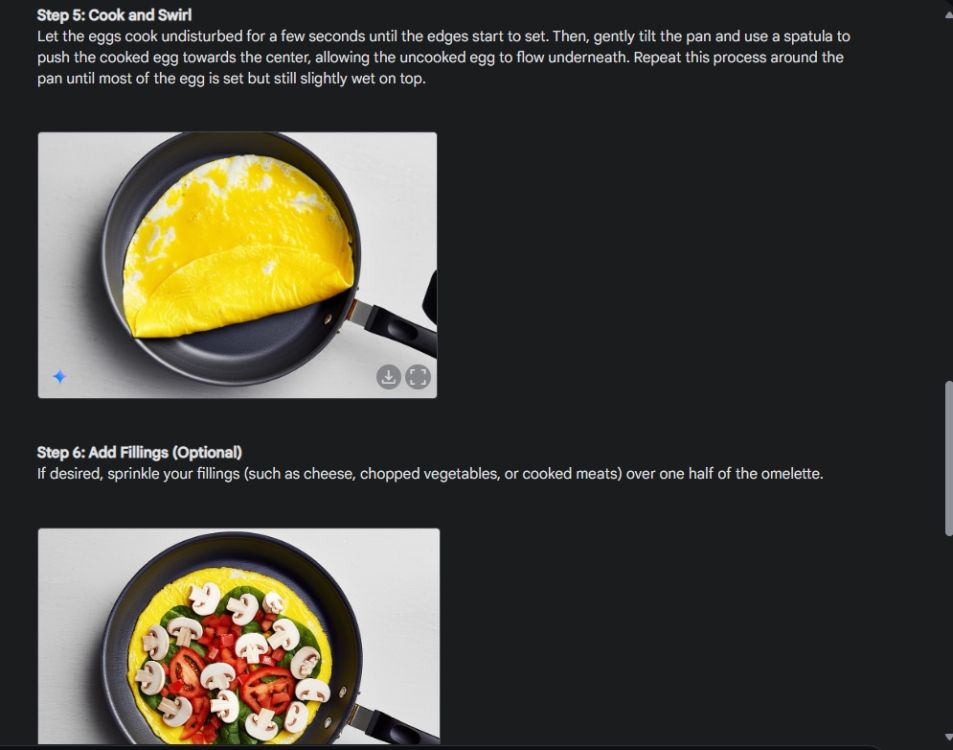
Comme vous pouvez le voir, les résultats sont très cohérents sur toutes les images sans aucune erreur. Même le bol est le même que sur la deuxième photo. Enfin, vous pouvez télécharger des images en résolution 1024 x 680. De cette façon, vous pouvez créer un guide visuel pour tout ce que vous voulez.
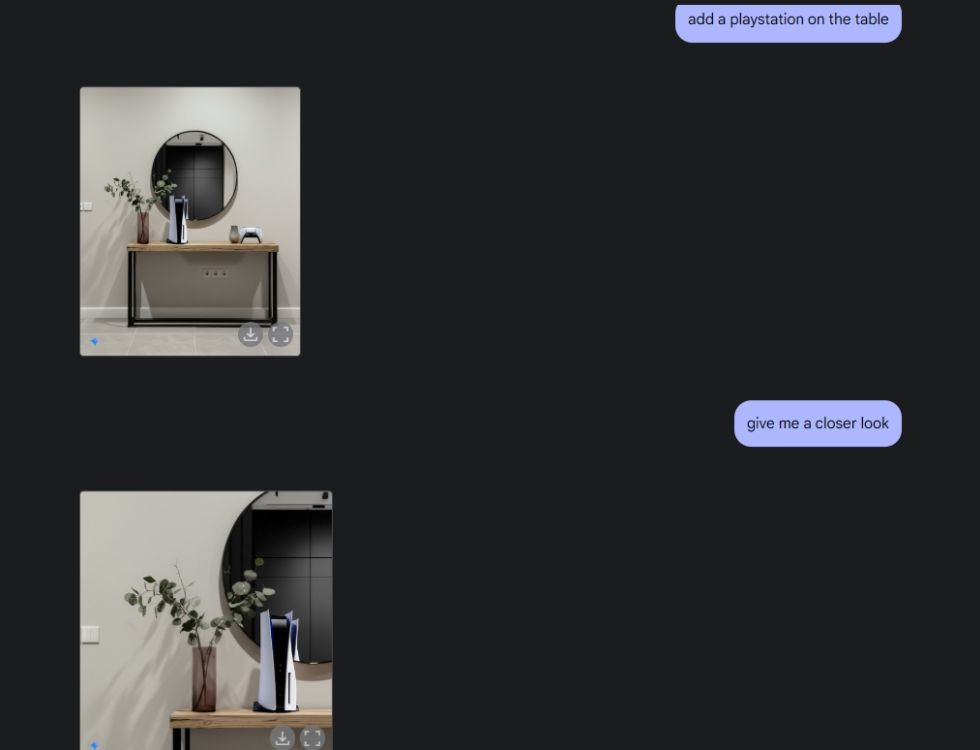
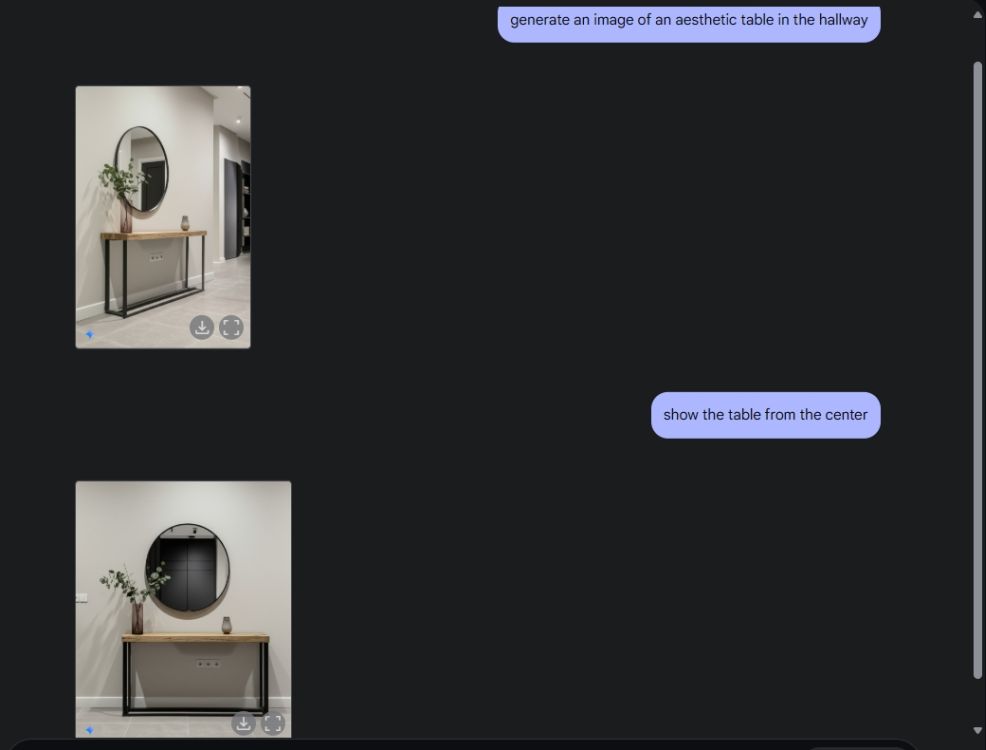
Ensuite, j'ai demandé à Gemini de créer une image de table esthétique, puis de visualiser la table sous l'angle de la caméra centrale. Il a fait un travail parfait. Ensuite, j’ai demandé à Gemini d’ajouter une PlayStation à la table et d’y regarder de plus près. Une fois de plus, Gemini a réussi. Comme vous pouvez le voir ci-dessous, le modèle d'IA incluait également un reflet de la PS5 dans le miroir derrière elle.
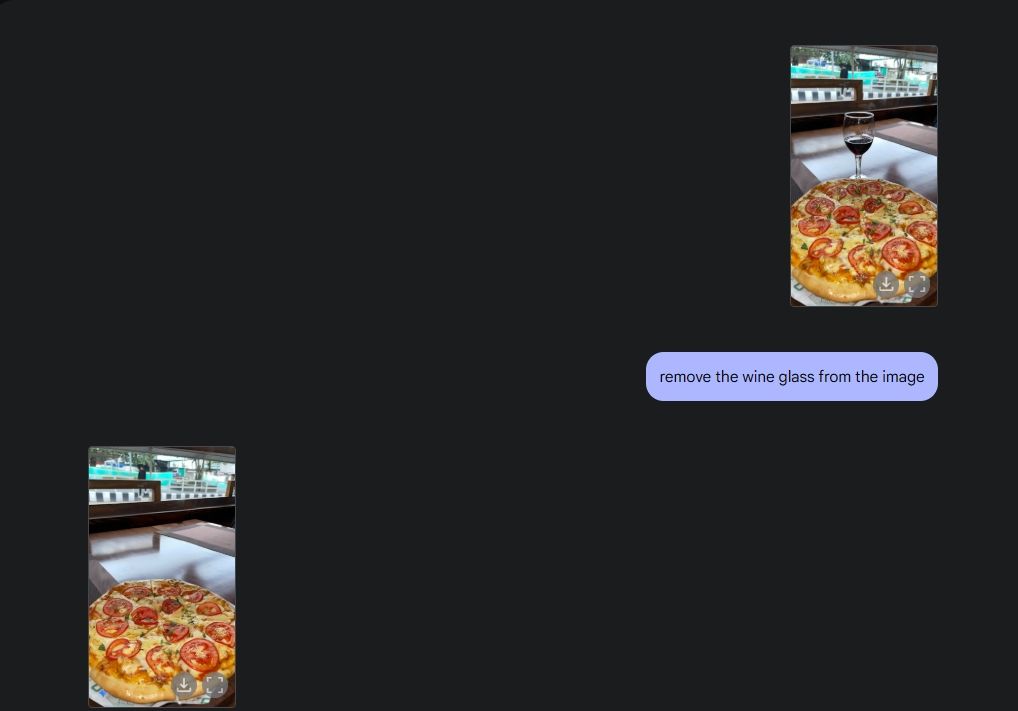
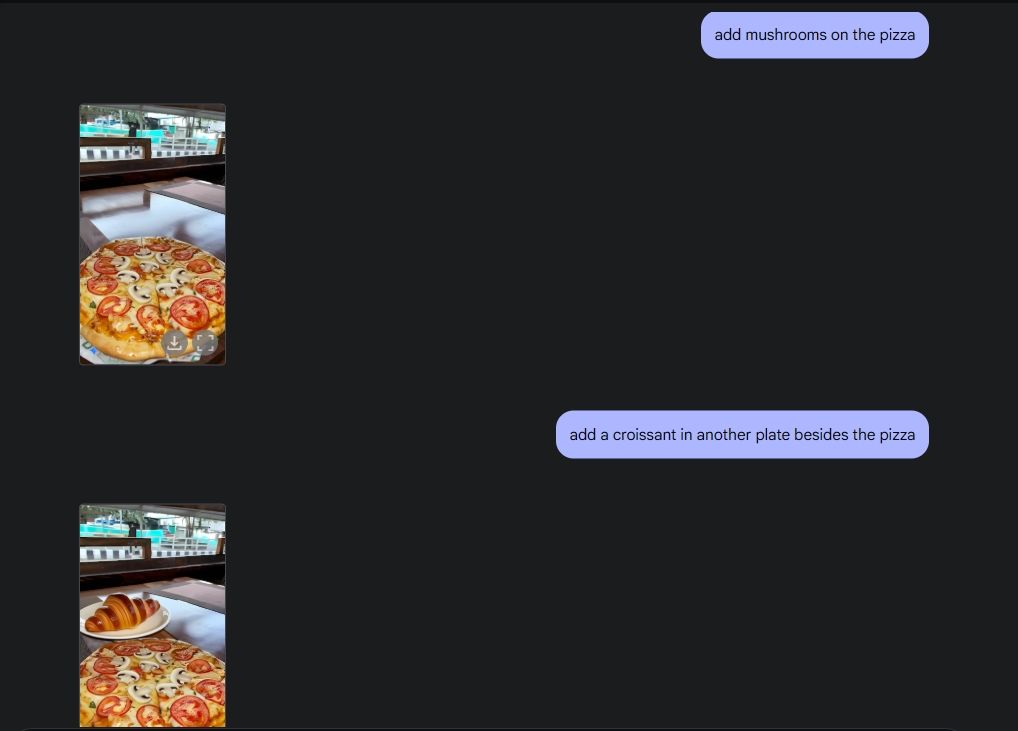
Pour démontrer la modification de la photo originale, j'ai téléchargé une photo de ma galerie et j'ai demandé à Gemini 2.0 de retirer le verre à vin de la table. Ensuite, j’ai demandé à Gemini d’ajouter des champignons à la pizza, et il a fait un excellent travail. J'ai ensuite demandé à Gemini d'ajouter un croissant, et voilà, l'édition photo IA avec toutes ses fonctionnalités, grâce aux capacités multimédias de Gemini.
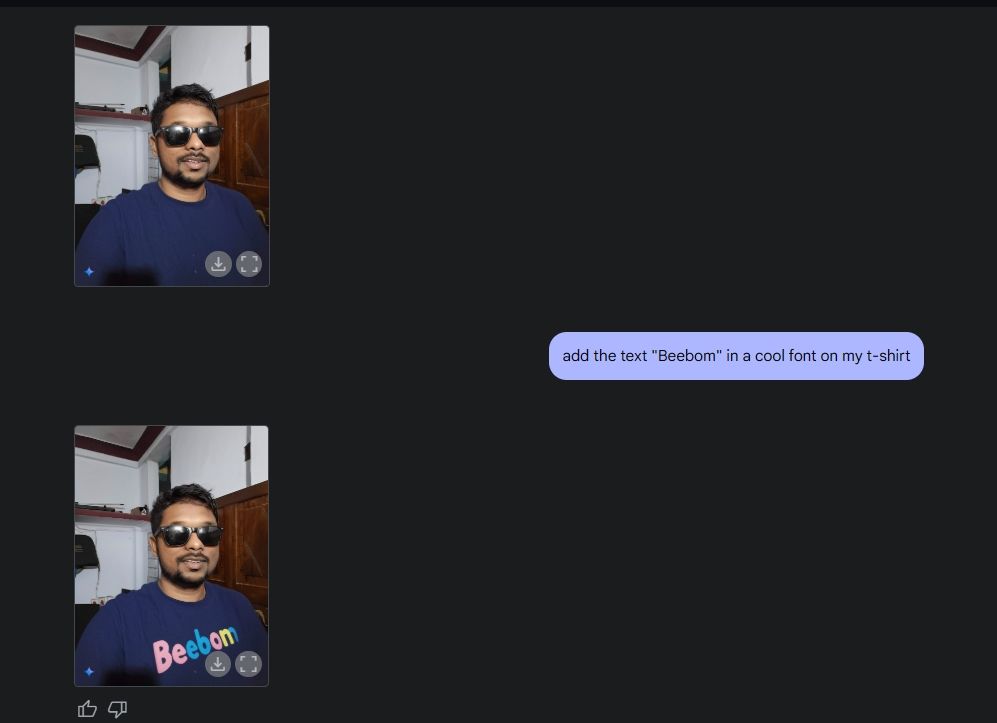
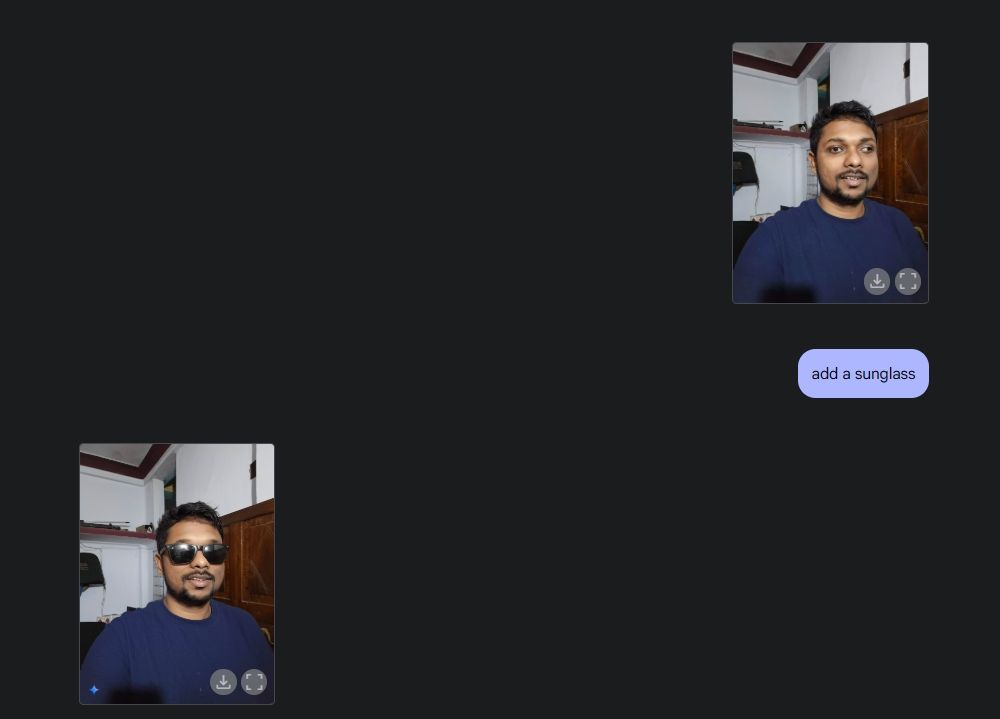
Ensuite, j’ai téléchargé une photo de moi, j’ai demandé à Gemini d’ajouter des lunettes de soleil, puis j’ai ajouté le texte « Beebom » sur ma chemise. Les deux ont été très bien exécutés.
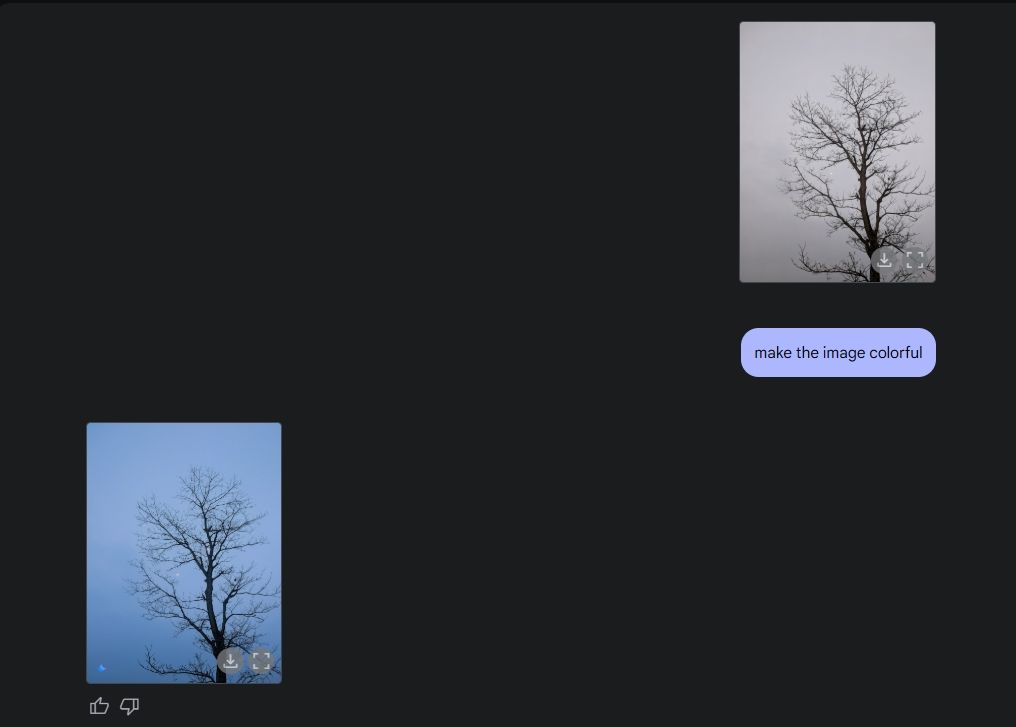
Finalement, j'ai demandé à Gemini de colorier une image, et il a bien réussi à le faire aussi. Je veux dire, l'image est plus belle qu'avant, sans aucune erreur étrange, distorsion ou partie manquante de l'image.
Il existe de nombreux cas d'utilisation que vous pouvez découvrir avec les nouvelles capacités multimédias de Gemini. Google a fait un excellent travail avec la création et l’édition d’images natives, et je prévois de l’utiliser plus en profondeur dans les semaines à venir pour tester ses limites.
Après avoir sorti Veo 2 pour la création vidéo et Imagen 3 pour la création d'images spécialisées, Google semble avoir surpassé OpenAI dans de nombreux domaines ; Pas seulement dans le domaine de la génération de texte par IA. Il sera donc intéressant de voir ce que OpenAI fera pour reprendre la tête avec ChatGPT.
Les commentaires sont fermés.