

Meta enseigne aux modèles d’IA l’art de distinguer les commandes importantes des autres.
Les modèles de raisonnement comme OpenAI o1 et DeepSeek-R1 ont un problème de réflexion excessive. Si vous lui posez une question simple comme « Combien font 1 + 1 ? », elle réfléchira plusieurs secondes avant de répondre.

Idéalement, les modèles d’IA, comme les humains, devraient être capables de déterminer quand fournir une réponse directe et quand allouer du temps et des ressources supplémentaires pour réfléchir avant de répondre. Et ça le fait nouvelle technologie Présenté par des chercheurs de Méta IA وUniversité de l'Illinois à Chicago En formant des modèles pour allouer des budgets d’inférence en fonction de la difficulté des requêtes. Cela se traduit par des réponses plus rapides, des coûts réduits et une meilleure allocation des ressources informatiques.
raisonnement coûteux
Les grands modèles de langage (LLM) peuvent améliorer leurs performances dans les tâches de raisonnement lorsqu'ils produisent des chaînes de pensée plus longues, souvent appelées « chaînes de pensée » (CoT). Le succès de la technique de la chaîne d’idées a conduit à toute une série de techniques de mise à l’échelle du temps d’inférence qui obligent le modèle à « réfléchir » plus profondément au problème, à générer et à examiner plusieurs réponses et à choisir la meilleure.
Le vote majoritaire (VM) est l’une des principales méthodes utilisées dans les modèles de raisonnement, où plusieurs réponses sont générées et la réponse la plus fréquemment posée est choisie. Le problème avec cette approche est que le modèle adopte un comportement uniforme, traitant chaque entrée comme un problème de raisonnement difficile et consommant des ressources inutiles pour générer plusieurs réponses.
Raisonnement intelligent
Le nouveau document de recherche propose une série de techniques de formation qui rendent les modèles de raisonnement plus efficaces pour répondre. La première étape est le « vote séquentiel » (VS), où le modèle interrompt le processus de raisonnement une fois qu’une réponse particulière est apparue un certain nombre de fois. Par exemple, le formulaire est invité à générer un maximum de huit réponses et à choisir la réponse qui apparaît au moins trois fois. Si le modèle reçoit la requête simple ci-dessus, les trois premières réponses sont susceptibles d'être similaires, ce qui conduit à un arrêt prématuré, à un gain de temps et à des ressources de calcul.
Leurs expériences montrent que SV surpasse le MV classique sur les problèmes de compétition mathématique lorsqu'il génère le même nombre de réponses. Cependant, SV nécessite des instructions supplémentaires et une génération de code, ce qui le place au même niveau que MV en termes de rapport code/précision.
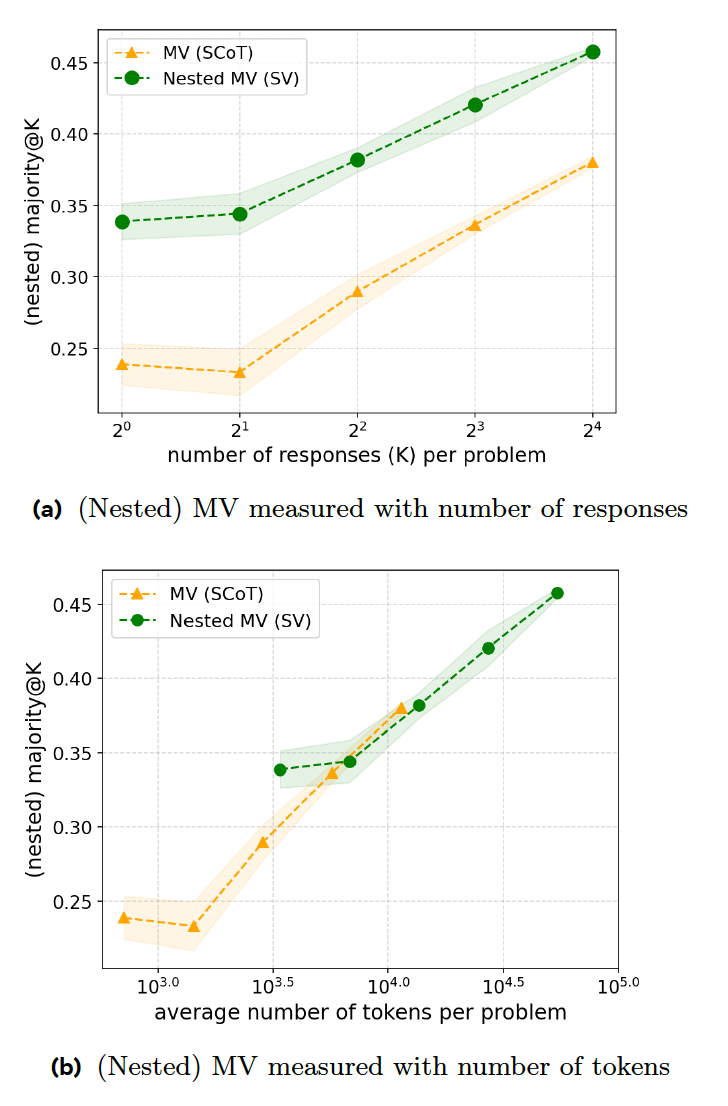
La deuxième technique, le vote séquentiel adaptatif (ASV), améliore le SV en exigeant que le modèle examine le problème et génère plusieurs réponses uniquement lorsque le problème est difficile. Pour les problèmes simples (comme une réclamation 1+1), le modèle génère simplement une seule réponse sans passer par le processus de vote. Cela rend le modèle plus efficace dans la gestion des problèmes simples et complexes.
Apprentissage par renforcement
Bien que les techniques SV et ASV améliorent toutes deux l’efficacité du modèle, elles nécessitent une grande quantité de données étiquetées manuellement. Pour atténuer ce problème, les chercheurs proposent « l’optimisation des politiques à budget d’inférence contraint » (IBPO), un algorithme d’apprentissage par renforcement qui apprend au modèle à ajuster la longueur des chemins de raisonnement en fonction de la difficulté de la requête.
L'IBPO est conçu pour permettre aux grands modèles linguistiques (LLM) d'améliorer leurs réponses tout en restant dans les contraintes du budget d'inférence. L'algorithme d'apprentissage par renforcement permet au modèle de dépasser les gains obtenus par l'entraînement sur des données étiquetées manuellement en générant en continu des trajectoires ASV, en évaluant les réponses et en sélectionnant les résultats qui fournissent la bonne réponse et le budget d'inférence optimal.
Leurs expériences montrent que l’IBPO améliore le front de Pareto, ce qui signifie que pour un budget d’inférence fixe, un modèle formé sur l’IBPO surpasse les autres lignes de base.
Ces résultats interviennent alors que les chercheurs avertissent que les modèles d’IA actuels sont en difficulté. Alors que les entreprises ont du mal à trouver des données de formation de haute qualité et à explorer d’autres moyens d’améliorer leurs modèles.
Une solution prometteuse est l’apprentissage par renforcement, où le modèle reçoit un objectif et est autorisé à trouver ses propres solutions, par opposition au réglage fin supervisé (SFT), où le modèle est formé sur des exemples étiquetés à la main.
Étonnamment, le modèle trouve souvent des solutions auxquelles les humains n’avaient pas pensé. C’est une formule qui semble avoir fonctionné avec DeepSeek-R1, qui a remis en cause la domination des laboratoires d’IA américains.
Les chercheurs constatent que « les méthodes basées sur les invites et la SFT peinent à atteindre une optimisation et une efficacité absolues, ce qui conforte l'hypothèse selon laquelle la SFT seule ne permet pas l'autocorrection. Cette observation est également corroborée par des travaux concurrents, qui suggèrent que ce comportement d'autocorrection apparaît spontanément pendant l'apprentissage par renforcement plutôt que d'être généré manuellement par les invites ou la SFT. »
Les commentaires sont fermés.